In this post, we shall make a few experimental observations about the 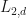 -spectral radius and dimensionality reduction that give evidence that the -spectral radius and dimensionality reduction will eventually have a deep mathematical theory behind it and also become more applicable to machine learning. I have not been able to prove these empirical observations, so one should consider this post to be about experimental mathematics. Hopefully these experimental results will eventually be backed up by formal theoretical mathematics. The reader is referred to this post for definitions.
-spectral radius and dimensionality reduction that give evidence that the -spectral radius and dimensionality reduction will eventually have a deep mathematical theory behind it and also become more applicable to machine learning. I have not been able to prove these empirical observations, so one should consider this post to be about experimental mathematics. Hopefully these experimental results will eventually be backed up by formal theoretical mathematics. The reader is referred to this post for definitions.
This post is currently a work in progress, so I will be updating this post with more information. Let  be the collection of all tuples
be the collection of all tuples  where
where  is not nilpotent. Given matrices
is not nilpotent. Given matrices  , define a function
, define a function  by letting
by letting 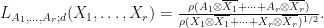
Given matrices  , we say that
, we say that  is an -spectral radius dimensionality reduction of if
is an -spectral radius dimensionality reduction of if  locally maximizes
locally maximizes  . We say that an -spectral radius dimensionality reduction is optimal if globally maximizes .
. We say that an -spectral radius dimensionality reduction is optimal if globally maximizes .
We say that is projectively similar to  if there is some
if there is some  and some
and some  where
where 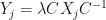 for
for  Let
Let  denote the equivalence relation where we set
denote the equivalence relation where we set 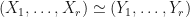 precisely when and are projectively similar. Let
precisely when and are projectively similar. Let ![[X_1,\dots,X_r]](https://s0.wp.com/latex.php?latex=%5BX_1%2C%5Cdots%2CX_r%5D&bg=ffffff&fg=111111&s=0&c=20201002) denote the equivalence relation with respect to
denote the equivalence relation with respect to 
Observation: (apparent unique local optimum; global attractor) Suppose that  are -SRDRs of obtained by gradient ascent on the domain
are -SRDRs of obtained by gradient ascent on the domain 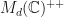 . Then are usually projectively similar. Suppose now that
. Then are usually projectively similar. Suppose now that 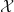 is the random variable consisting of all equivalence classes where is an -SRDR trained by some variant of gradient ascent. Then our computations indicate that the random variable has typically has low entropy in the case when is a non-constant random variable.
is the random variable consisting of all equivalence classes where is an -SRDR trained by some variant of gradient ascent. Then our computations indicate that the random variable has typically has low entropy in the case when is a non-constant random variable.
Example: The above observation does not always hold as  may have multiple non-projectively similar local maxima. For example, suppose that
may have multiple non-projectively similar local maxima. For example, suppose that 
 for
for  where each
where each 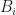 and each
and each  is a
is a  -matrix. Then
-matrix. Then  Suppose now that
Suppose now that  and
and  . Then
. Then  are usually non-projectively similar local maxima for the function
are usually non-projectively similar local maxima for the function  Of course, does not generate the algebra
Of course, does not generate the algebra  , but there is some neighborhood
, but there is some neighborhood  of where if
of where if  , then
, then  will have at least two non-projectively similar local maxima. This sort of scenario is not as contrived as one may think it is since
will have at least two non-projectively similar local maxima. This sort of scenario is not as contrived as one may think it is since  could represent two clusters where there are few or weak connections between these clusters (for example, in natural language processing, each language could represent its own cluster).
could represent two clusters where there are few or weak connections between these clusters (for example, in natural language processing, each language could represent its own cluster).
Observation: (height and breadth correlation for local maxima) Suppose that is the probability distribution of the (real, complex,or quaternionic) equivalence classes of -SRDRs obtained from using gradient ascent. Then the random variables  (mapping the outcome to the probability of observing that outcome) and
(mapping the outcome to the probability of observing that outcome) and  tend to have a positive linear correlation. The probability
tend to have a positive linear correlation. The probability ![P([X_1,\dots,X_r])](https://s0.wp.com/latex.php?latex=P%28%5BX_1%2C%5Cdots%2CX_r%5D%29&bg=ffffff&fg=111111&s=0&c=20201002) is maximized typically when
is maximized typically when  is maximized instead of just locally maximized.
is maximized instead of just locally maximized.
Observation: (preservation of symmetry) Suppose that  are Hermitian (resp. real, real symmetric, complex symmetric, positive semidefinite) and is an -SRDR of . Then is usually projectively similar to some tuple where each
are Hermitian (resp. real, real symmetric, complex symmetric, positive semidefinite) and is an -SRDR of . Then is usually projectively similar to some tuple where each  is Hermitian (resp. real, real symmetric, complex symmetric, positive semidefinite).
is Hermitian (resp. real, real symmetric, complex symmetric, positive semidefinite).
Observation: (near functoriality) Suppose that  Suppose that generates
Suppose that generates  Let
Let 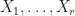 be an
be an  -SRDR of . Let
-SRDR of . Let  be an -SRDR of . Let
be an -SRDR of . Let  be an -SRDR of . Then
be an -SRDR of . Then 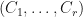 is usually not projectively similar to , but
is usually not projectively similar to , but ![[C_1,\dots,C_r]](https://s0.wp.com/latex.php?latex=%5BC_1%2C%5Cdots%2CC_r%5D&bg=ffffff&fg=111111&s=0&c=20201002) is usually close to
is usually close to ![[X_1,\dots,X_r].](https://s0.wp.com/latex.php?latex=%5BX_1%2C%5Cdots%2CX_r%5D.&bg=ffffff&fg=111111&s=0&c=20201002)
Observation: (Suboptimal real LSRDRs) Suppose that  . Let
. Let  be the restriction of to the domain
be the restriction of to the domain 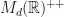 . A local maxima for
. A local maxima for  shall be called a real LSRDR. Gradient ascent for the function often produces more local maxima which are not global maxima than the complex version has. These supoptimal local optima are tuples where if
shall be called a real LSRDR. Gradient ascent for the function often produces more local maxima which are not global maxima than the complex version has. These supoptimal local optima are tuples where if  has eigenvalues
has eigenvalues  with
with  , then
, then  are complex conjugates. In this case,
are complex conjugates. In this case,  , but
, but  is not as large as it can be since the gradient ascent process must make the absolute value of two eigenvalues
is not as large as it can be since the gradient ascent process must make the absolute value of two eigenvalues  large instead of simply making the absolute value of a single eigenvalue large. Fortunately, the most efficient way of computing real LSRDRs also naturally avoids the case when
large instead of simply making the absolute value of a single eigenvalue large. Fortunately, the most efficient way of computing real LSRDRs also naturally avoids the case when  . To compute LSRDRs, one will need to compute the gradient of the expression
. To compute LSRDRs, one will need to compute the gradient of the expression  , but the most efficient way to compute the gradient of the spectral radius of a matrix
, but the most efficient way to compute the gradient of the spectral radius of a matrix 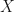 , one will need to use the dominant left and right eigenvectors of . The dominant left and right eigenvectors of can be computed using a power iteration, but the power iteration technique (unless generalized) only effectively computes the dominant left and right eigenvectors of if has a single eigenvector
, one will need to use the dominant left and right eigenvectors of . The dominant left and right eigenvectors of can be computed using a power iteration, but the power iteration technique (unless generalized) only effectively computes the dominant left and right eigenvectors of if has a single eigenvector  where
where  whenever
whenever 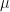 is an eigenvalue different than
is an eigenvalue different than  Therefore, a variation of gradient ascent that uses the dominant left and right eigenvectors to approximate the gradient of will be inaccurate whenever has multiple dominant eigenvectors. In practice, the gradient ascent process will still converge, but it will converge to a value where has a single dominant eigenvalue. In this case, the gradient ascent process avoids supoptimal real LSRDRs. With everything being said, there are still examples (such as with MPO word embeddings) of real matrices where training a complex LSRDR achieves better results than training a real LSRDR and where if is a complex LSRDR, then there are
Therefore, a variation of gradient ascent that uses the dominant left and right eigenvectors to approximate the gradient of will be inaccurate whenever has multiple dominant eigenvectors. In practice, the gradient ascent process will still converge, but it will converge to a value where has a single dominant eigenvalue. In this case, the gradient ascent process avoids supoptimal real LSRDRs. With everything being said, there are still examples (such as with MPO word embeddings) of real matrices where training a complex LSRDR achieves better results than training a real LSRDR and where if is a complex LSRDR, then there are  where
where  is a real matrix for
is a real matrix for 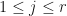 .
.
If 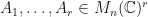 , then define a function
, then define a function  by setting
by setting 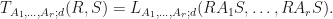
We say that  is an -SRDR projector if is a local maximum for
is an -SRDR projector if is a local maximum for  . We say that is a strong -SRDR projector if
. We say that is a strong -SRDR projector if  is an -SRDR.
is an -SRDR.
Observation: If is an -SRDR projector, then there is usually a constant with  and a projection
and a projection 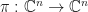 of rank
of rank 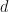 with
with  -SRDRs projectors are usually strong -SRDR projectors. If
-SRDRs projectors are usually strong -SRDR projectors. If 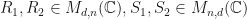 , then set
, then set ![[[R_1,S_1]]=[[R_2,S_2]]](https://s0.wp.com/latex.php?latex=%5B%5BR_1%2CS_1%5D%5D%3D%5B%5BR_2%2CS_2%5D%5D&bg=ffffff&fg=111111&s=0&c=20201002) precisely when there are
precisely when there are  where
where  . If
. If 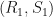 and
and  are -SRDR projectors, then we typically have
are -SRDR projectors, then we typically have ![[[R_1,S_1]]=[[R_2,S_2]].](https://s0.wp.com/latex.php?latex=%5B%5BR_1%2CS_1%5D%5D%3D%5B%5BR_2%2CS_2%5D%5D.&bg=ffffff&fg=111111&s=0&c=20201002) In fact,
In fact,  for some
for some  and if we set
and if we set 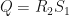 , then for some .
, then for some .
We say that a -SRDR projector is constant factor normalized if  . If
. If  are two constant factor normalized -SRDR projectors of , then
are two constant factor normalized -SRDR projectors of , then  and where if we set , then
and where if we set , then  Furthermore, we typically have
Furthermore, we typically have  We shall call the projection matrix
We shall call the projection matrix  an -LSRDR projection operator of
an -LSRDR projection operator of 
Observation: Let be a constant factor normalized -SRDR projector of , and suppose that 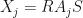 for . Let
for . Let  and suppose that
and suppose that  is a projection matrix. Let
is a projection matrix. Let  be a dominant eigenvector of
be a dominant eigenvector of  and let
and let  be a dominant eigenvector of
be a dominant eigenvector of  . Then in our experiments, the matrices
. Then in our experiments, the matrices  can all be written as positive semidefinite matrices multiplied by a complex constant.
can all be written as positive semidefinite matrices multiplied by a complex constant.
The eigenvalues of  are all simple eigenvalues.
are all simple eigenvalues.
Let  be random complex
be random complex  -positive semidefinite matrices. Let
-positive semidefinite matrices. Let  and let
and let  for
for  . Then the sequence
. Then the sequence  converges to a positive semidefinite matrix
converges to a positive semidefinite matrix 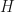 and the sequence
and the sequence 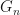 converges to a positive semidefinite matrix
converges to a positive semidefinite matrix 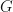 . The positive semidefinite matrices
. The positive semidefinite matrices  do not depend on the initialization
do not depend on the initialization  There exists complex constants
There exists complex constants  where
where  and
and  .
.
Here,  , and
, and  and
and  .
.
Let  be random complex -positive semidefinite matrices. Let
be random complex -positive semidefinite matrices. Let  and let
and let  for . Then
for . Then  .
.
The matrix is the dominant eigenvector of the superoperator . The matrix is the dominant eigenvector of the superoperator  . The matrix is the dominant eigenvector of the superoperator
. The matrix is the dominant eigenvector of the superoperator  The matrix is the dominant eigenvector of the superoperator
The matrix is the dominant eigenvector of the superoperator  . Furthermore, we have
. Furthermore, we have  . These eigenvectors correspond to real positive eigenvalues:
. These eigenvectors correspond to real positive eigenvalues:  and
and 
Application: LSRDRs may be used to compress data that can be represented as a collection of matrices. Suppose that is a collection of matrices. Let be a constant factor normalized -SRDR of . Let for . Then the matrices can be approximately recovered from and . The matrix  is an approximation for the matrix
is an approximation for the matrix  which we shall call an LSRDR principal component (LSRDRPC) for . We observe that if are two constant factor normalized -SRDRs of , then since
which we shall call an LSRDR principal component (LSRDRPC) for . We observe that if are two constant factor normalized -SRDRs of , then since  , we have
, we have  . In other word, the LSRDRPC for is typically unique or at the very least, there will be few LSRDRPCs for
. In other word, the LSRDRPC for is typically unique or at the very least, there will be few LSRDRPCs for 
Observation: If is an -SRDR of , then there is usually a strong -SRDR projector where for
Observation: If are self-adjoint, then whenever is a constant factor normalized -SRDR projector of , we usually have ![[[R,S]]=[[R_1,S_1]]](https://s0.wp.com/latex.php?latex=%5B%5BR%2CS%5D%5D%3D%5B%5BR_1%2CS_1%5D%5D&bg=ffffff&fg=111111&s=0&c=20201002) for some -SRDR projector of with
for some -SRDR projector of with 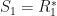 and where
and where  . Furthermore, if
. Furthermore, if ![[[R_2,S_2]]](https://s0.wp.com/latex.php?latex=%5B%5BR_2%2CS_2%5D%5D&bg=ffffff&fg=111111&s=0&c=20201002) is another -SRDR projector of with
is another -SRDR projector of with 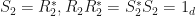 , then
, then  is a unitary matrix, and
is a unitary matrix, and 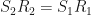 , and
, and 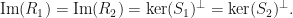 If
If  is the inclusion mapping, and
is the inclusion mapping, and  is the orthogonal projection, then
is the orthogonal projection, then ![[[\iota,j]]](https://s0.wp.com/latex.php?latex=%5B%5B%5Ciota%2Cj%5D%5D&bg=ffffff&fg=111111&s=0&c=20201002) is an -SRDR projector.
is an -SRDR projector.
Observation: If are real square matrices, then whenever is a -SRDR projector of , we usually have for some -SRDR projector of where  are real matrices. Furthermore, if are real constant factor normalized -SRDR projectors of , then there is a real matrix
are real matrices. Furthermore, if are real constant factor normalized -SRDR projectors of , then there is a real matrix 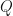 where
where  .
.
Observation: If are real symmetric matrices, then whenever is a -SRDR projector of , we usually have for some -SRDR projector of where are real matrices with  . In fact, if are real constant factor normalized -SRDR projectors of with
. In fact, if are real constant factor normalized -SRDR projectors of with  , there is a real orthogonal matrix with .
, there is a real orthogonal matrix with .
Observation: If are complex symmetric matrices, then whenever is a -SRDR projector of , we usually have for some -SRDR projector of and where  . Furthermore, if are constant factor normalized -SRDR projectors of , and , then
. Furthermore, if are constant factor normalized -SRDR projectors of , and , then  .
.
Application: Dimensionality reduction of various manifolds. Let  denote the quotient complex manifold
denote the quotient complex manifold  where we set
where we set  precisely when
precisely when  or
or  . One can use our observations about LSRDRs to perform dimensionality reduction of data in
. One can use our observations about LSRDRs to perform dimensionality reduction of data in  , and we can also use dimensionality reduction to map data in
, and we can also use dimensionality reduction to map data in  and
and 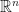 to data in
to data in  and
and 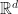 respectively.
respectively.
Let 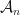 be the collection of all positive definite rank-1 real matrices. Let
be the collection of all positive definite rank-1 real matrices. Let  be the collection of all positive definite rank-1 complex matrices. Let
be the collection of all positive definite rank-1 complex matrices. Let 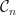 be the collection of all symmetric rank-1 complex matrices. The sets
be the collection of all symmetric rank-1 complex matrices. The sets 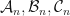 can be put into a canonical one-to-one correspondence with respectively. Suppose that
can be put into a canonical one-to-one correspondence with respectively. Suppose that  and is an -SRDR of . If
and is an -SRDR of . If 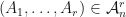 , then
, then ![[X_1,\dots,X_r]\cap\mathcal{A}_d^r\neq\emptyset](https://s0.wp.com/latex.php?latex=%5BX_1%2C%5Cdots%2CX_r%5D%5Ccap%5Cmathcal%7BA%7D_d%5Er%5Cneq%5Cemptyset&bg=ffffff&fg=111111&s=0&c=20201002) , and every element of
, and every element of ![[X_1,\dots,X_r]\cap\mathcal{A}_d^r](https://s0.wp.com/latex.php?latex=%5BX_1%2C%5Cdots%2CX_r%5D%5Ccap%5Cmathcal%7BA%7D_d%5Er&bg=ffffff&fg=111111&s=0&c=20201002) can be considered as a dimensionality reduction of . Similarly, if
can be considered as a dimensionality reduction of . Similarly, if  , then
, then ![[X_1,\dots,X_r]\cap\mathcal{B}_d^r\neq\emptyset](https://s0.wp.com/latex.php?latex=%5BX_1%2C%5Cdots%2CX_r%5D%5Ccap%5Cmathcal%7BB%7D_d%5Er%5Cneq%5Cemptyset&bg=ffffff&fg=111111&s=0&c=20201002) , and if
, and if  , then
, then ![[X_1,\dots,X_r]\cap\mathcal{C}_d^r\neq\emptyset](https://s0.wp.com/latex.php?latex=%5BX_1%2C%5Cdots%2CX_r%5D%5Ccap%5Cmathcal%7BC%7D_d%5Er%5Cneq%5Cemptyset&bg=ffffff&fg=111111&s=0&c=20201002) .
.
-SRDRs can be used to produce dimensionality reductions that map subsets  to
to 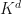 where
where 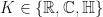 .
.
Suppose that  . Then let
. Then let  for
for  . Then there is some subspace
. Then there is some subspace  where if
where if 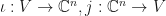 are the inclusion and projection mappings, then
are the inclusion and projection mappings, then  is a constant factor normalized -SRDR projector for . In this case,
is a constant factor normalized -SRDR projector for . In this case, 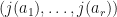 is a dimensionality reduction of the tuple
is a dimensionality reduction of the tuple 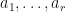 .
.
Suppose that . Then let  for . Suppose that is a constant factor normalized -SRDR projector with respect to . Then
for . Suppose that is a constant factor normalized -SRDR projector with respect to . Then 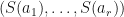 is a dimensionality reduction of
is a dimensionality reduction of 
One may need to normalize the data 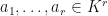 in the above paragraphs before taking a dimensionality reduction. Suppose that
in the above paragraphs before taking a dimensionality reduction. Suppose that  . Let
. Let  be the mean of
be the mean of 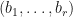 . Let
. Let 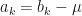 . Suppose that
. Suppose that  is a dimensionality reduction of
is a dimensionality reduction of  . Then
. Then  is normalized dimensionality reduction of .
is normalized dimensionality reduction of .
Application: (clustering for neural networks with bilinear layers) Suppose that 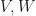 are finite dimensional real inner product spaces. We say that a function
are finite dimensional real inner product spaces. We say that a function  is a quadratic form if
is a quadratic form if  is a quadratic form for each
is a quadratic form for each  . We say that a linear operator
. We say that a linear operator  is symmetric if
is symmetric if  is a symmetric linear operator for each
is a symmetric linear operator for each  . The quadratic forms can be put into a one-to-one correspondence with the symmetric linear operators by the relation
. The quadratic forms can be put into a one-to-one correspondence with the symmetric linear operators by the relation  for
for 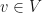 .
.
Suppose that is a quadratic form and is a linear mapping such that for  Suppose furthermore that
Suppose furthermore that  is an LSRDR of
is an LSRDR of  . Let
. Let 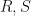 be the linear operators where
be the linear operators where  and suppose that
and suppose that  . Then let . Then is an orthogonal projection operator, and the space
. Then let . Then is an orthogonal projection operator, and the space  is a cluster in
is a cluster in  . Furthermore, let be the dominant eigenvector of
. Furthermore, let be the dominant eigenvector of  and let be the dominant eigenvector of
and let be the dominant eigenvector of  . Then we may assume that the operators
. Then we may assume that the operators  are positive semidefinite with trace 1. Then whenever
are positive semidefinite with trace 1. Then whenever  , the values
, the values  and
and  are measures of how well the vector
are measures of how well the vector  belongs to the cluster .
belongs to the cluster .
Observation: (Random real matrices) Suppose that  and
and  are random real matrices; for simplicity assume that the entries in
are random real matrices; for simplicity assume that the entries in  are independent, and normally distributed with mean
are independent, and normally distributed with mean 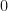 and variance
and variance  . Then whenever
. Then whenever 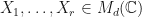 , we have
, we have  . In particular,
. In particular,  .
.
Observation: (Random complex matrices) Suppose now that and 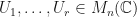 are random complex matrices; for simplicity assume that the entries in are independent, Gaussian with mean , where the real part of each entry in
are random complex matrices; for simplicity assume that the entries in are independent, Gaussian with mean , where the real part of each entry in  has variance
has variance 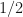 and the imaginary part of each entry in has variance . Then and .
and the imaginary part of each entry in has variance . Then and .
Observation: (Random permutation matrices) Suppose that and  is the standard irreducible representation. Let
is the standard irreducible representation. Let  be selected uniformly at random. Then
be selected uniformly at random. Then 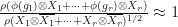 and
and 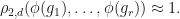
Observation: (Random orthogonal or unitary matrices): Suppose that , and let  be a collection of unitary matrices select at random according to the Haar measure or let be a collection of orthogonal matrices selected at random according to the Haar measure. Then
be a collection of unitary matrices select at random according to the Haar measure or let be a collection of orthogonal matrices selected at random according to the Haar measure. Then  and
and  .
.
Suppose that is a complex matrix with eigenvalues  with
with  . Then define the spectral gap ratio of as
. Then define the spectral gap ratio of as 
Observation: Let  . Let be random matrices according to some distribution. Suppose that
. Let be random matrices according to some distribution. Suppose that 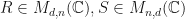 are matrices where
are matrices where  is positive semidefinite (for example, could be a constant factor normalized LSRDR projector of ). Let
is positive semidefinite (for example, could be a constant factor normalized LSRDR projector of ). Let  . Suppose that the eigenvalues of are
. Suppose that the eigenvalues of are  with
with  Then the spectral gap ratio of is much larger than the spectral gap of ratio random matrices that follow the circular law. However, the eigenvalues
Then the spectral gap ratio of is much larger than the spectral gap of ratio random matrices that follow the circular law. However, the eigenvalues  with the dominant eigenvalue
with the dominant eigenvalue 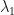 removed still follow the circular law (or semicircular or elliptical law depending on the choice of distribution of ). The value
removed still follow the circular law (or semicircular or elliptical law depending on the choice of distribution of ). The value  will be approximately . The large spectral gap ratio for makes the version of gradient ascent that we use to compute LSRDRs work well; the power iteration algorithm for computing dominant eigenvectors converges more quickly if there is a large spectral gap ratio, and the dominant eigenvectors of a matrix are needed to calculate the gradient of the spectral radius of that matrix.
will be approximately . The large spectral gap ratio for makes the version of gradient ascent that we use to compute LSRDRs work well; the power iteration algorithm for computing dominant eigenvectors converges more quickly if there is a large spectral gap ratio, and the dominant eigenvectors of a matrix are needed to calculate the gradient of the spectral radius of that matrix.
Observation: Suppose that  is near zero. Suppose that are independent random complex matrices. Suppose furthermore that the entries in each
is near zero. Suppose that are independent random complex matrices. Suppose furthermore that the entries in each  are independent, Gaussian, and have variance
are independent, Gaussian, and have variance  . Then
. Then 
Observation: (increased regularity in high dimensions) Suppose that are -complex matrices. Suppose that  . Suppose that
. Suppose that 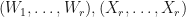 are -SRDRs of trained by gradient ascent while
are -SRDRs of trained by gradient ascent while  are -SRDRs of . Then it is more likely for to be projectively similar to
are -SRDRs of . Then it is more likely for to be projectively similar to 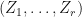 than it is for
than it is for 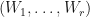 to be projectively similar to . In general, will be better behaved than .
to be projectively similar to . In general, will be better behaved than .
Application: (Iterated LSRDRs) Suppose that  . Let be -complex matrices. Suppose that
. Let be -complex matrices. Suppose that  for . Suppose furthermore that
for . Suppose furthermore that  is an LSRDR of
is an LSRDR of  whenever
whenever  . Then we shall call
. Then we shall call  an iterated LSRDR of . One advantage of iterated LSRDRs over LSRDRs is that an iterated LSRDR of where each
an iterated LSRDR of . One advantage of iterated LSRDRs over LSRDRs is that an iterated LSRDR of where each  is an
is an  -matrix is more likely to be well-behaved than an LSRDR of where each
-matrix is more likely to be well-behaved than an LSRDR of where each  is an -matrix. While iterated LSRDRs may seem to require more intensive computation than ordinary LSRDRs, it will take fewer rounds of gradient ascent to compute from than it will take to compute the LSRDR .
is an -matrix. While iterated LSRDRs may seem to require more intensive computation than ordinary LSRDRs, it will take fewer rounds of gradient ascent to compute from than it will take to compute the LSRDR .
Observation: (Increased regularity with more matrices) Suppose that  . Let
. Let  . Suppose that is an LSRDR of while
. Suppose that is an LSRDR of while  is an LSRDR of
is an LSRDR of  . Then the LSRDR is generally better behaved than the LSRDR
. Then the LSRDR is generally better behaved than the LSRDR  For example, if all the matrices
For example, if all the matrices  are real matrices, then it is more likely that one can find
are real matrices, then it is more likely that one can find  where
where  are all real matrices than it is to find where each
are all real matrices than it is to find where each  are all real matrices.
are all real matrices.
Application: (Appending matrix products) Suppose that are -complex matrices and  . Suppose that is an LSRDR of . If the LSRDR is poorly behaved, then one may modify to obtain a better behaved LSRDR.
. Suppose that is an LSRDR of . If the LSRDR is poorly behaved, then one may modify to obtain a better behaved LSRDR.
For example, if  , then set
, then set  . Suppose that
. Suppose that  are non-negative real numbers. Then let
are non-negative real numbers. Then let  . Then let
. Then let  be an LSRDR of
be an LSRDR of  . Then the LSRDR typically behaves better than the LSRDR . While each round of gradient ascent for computing the LSRDR takes longer than each round for computing the LSRDR , the gradient ascent will converge in fewer rounds for than it will for .
. Then the LSRDR typically behaves better than the LSRDR . While each round of gradient ascent for computing the LSRDR takes longer than each round for computing the LSRDR , the gradient ascent will converge in fewer rounds for than it will for .
Block preservation
Suppose that  are real or complex inner product spaces. Let
are real or complex inner product spaces. Let  . Let
. Let  be a linear operator for . Suppose that for each , there are
be a linear operator for . Suppose that for each , there are  where if
where if  and
and  , then
, then  . Let
. Let  be an LSRDR projection operator of . Then we may typically find projection operators
be an LSRDR projection operator of . Then we may typically find projection operators  for
for  with
with  .
.
Suppose now that  is a function. For
is a function. For 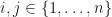 , let
, let  be the matrix where the
be the matrix where the  -th entry is
-th entry is  and every other entry is zero. Let
and every other entry is zero. Let  for , and let
for , and let  Let
Let  be an LSRDR projection operator of
be an LSRDR projection operator of  . If
. If  , then let
, then let  be the matrix where
be the matrix where  and where
and where  whenever
whenever  and where
and where 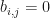 otherwise. If , then let
otherwise. If , then let  be the -diagonal matrix where the
be the -diagonal matrix where the 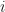 -th diagonal entry is for
-th diagonal entry is for  and the -th diagonal entry is whenever
and the -th diagonal entry is whenever  Then we typically have
Then we typically have  where
where 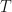 is the subset of
is the subset of  with
with  and where
and where  is maximized.
is maximized.
Application: Given a matrix , let  denote the sum of all the entries in
denote the sum of all the entries in  Suppose that
Suppose that 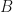 is a real -matrix. Then we may use LSRDRs to find a subset
is a real -matrix. Then we may use LSRDRs to find a subset  where
where  is maximized.
is maximized.
Let  be the -matrix where each entry is
be the -matrix where each entry is  , and let
, and let  . Let be a real -matrix. Then it is not too difficult to show that
. Let be a real -matrix. Then it is not too difficult to show that 
Suppose that is an -real matrix, and there is a unique with and where  is maximized. Then whenever is maximized,
is maximized. Then whenever is maximized,  is sufficiently small, and
is sufficiently small, and  , we typically have
, we typically have 
Quaternions
We say that a 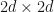 complex matrix is a quaternionic complex matrix if
complex matrix is a quaternionic complex matrix if 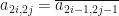 and
and 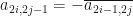 whenever
whenever 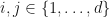 . Suppose that each is an quaternionic complex matrix for . Suppose that is an even integer with
. Suppose that each is an quaternionic complex matrix for . Suppose that is an even integer with  and suppose that is a -SRDR of . Then there is often some and where if we set for , then
and suppose that is a -SRDR of . Then there is often some and where if we set for , then  are quaternionic complex matrices. Furthermore, if is an -SRDR projector, then there is some LSRDR projector
are quaternionic complex matrices. Furthermore, if is an -SRDR projector, then there is some LSRDR projector ![[[R_1,S_1]]](https://s0.wp.com/latex.php?latex=%5B%5BR_1%2CS_1%5D%5D&bg=ffffff&fg=111111&s=0&c=20201002) where but where are quaternionic complex matrices.
where but where are quaternionic complex matrices.
We observe that if are quaternionic complex matrices and  are rectangular matrices with , then the matrix
are rectangular matrices with , then the matrix  will still have a single dominant eigenvalue with a spectral gap ratio significantly above 1 in contrast with the fact that each have spectral gap ratio of since the eigenvalues of come in conjugate pairs. In particular, if
will still have a single dominant eigenvalue with a spectral gap ratio significantly above 1 in contrast with the fact that each have spectral gap ratio of since the eigenvalues of come in conjugate pairs. In particular, if  are matrices obtained during the process of training , then the matrix
are matrices obtained during the process of training , then the matrix  will have a spectral gap ratio that is significantly above ; this ensures that gradient ascent will not have any problems in optimizing .
will have a spectral gap ratio that is significantly above ; this ensures that gradient ascent will not have any problems in optimizing .
Gradient ascent on subspaces
Let  be a natural number. Let
be a natural number. Let 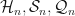 be the set of all -Hermitian matrices, complex symmetric matrices, and complex quaternionic matrices. Suppose that
be the set of all -Hermitian matrices, complex symmetric matrices, and complex quaternionic matrices. Suppose that  . Suppose that . Then let
. Suppose that . Then let  be a tuple such that
be a tuple such that  is locally maximized. Suppose that
is locally maximized. Suppose that 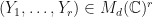 is a tuple where
is a tuple where 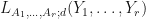 is locally maximized. Then we usually have
is locally maximized. Then we usually have 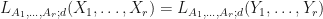 . In this case, we would say that is an alternate domain -spectral radius dimensionality reduction (ADLSRDR).
. In this case, we would say that is an alternate domain -spectral radius dimensionality reduction (ADLSRDR).
Homogeneous non-commutative polynomials
Suppose that  is a homogeneous non-commutative polynomial of degree . Define a fitness function
is a homogeneous non-commutative polynomial of degree . Define a fitness function  by letting
by letting  whenever
whenever 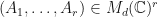 . We say that is an -spectral radius dimensionality reduction of if
. We say that is an -spectral radius dimensionality reduction of if  is maximized.
is maximized.
If  is a tensor of degree
is a tensor of degree 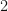 , then
, then  where
where  denotes the Frobenius norm of . One should take an LSRDR of an -tensor only if
denotes the Frobenius norm of . One should take an LSRDR of an -tensor only if  since there are plenty of linear algebraic tools that one can use to analyze -tensors.
since there are plenty of linear algebraic tools that one can use to analyze -tensors.
Suppose that is a homogeneous non-commutative polynomial of degree with random coefficients. Let be an LSRDR of . Then whenever  is a homogeneous non-commutative polynomial of degree
is a homogeneous non-commutative polynomial of degree  with
with  , we typically have
, we typically have  . Let
. Let  . The eigenvalues of
. The eigenvalues of  will be symmetric under
will be symmetric under  rotations. Whenever the coefficients of are random complex numbers and
rotations. Whenever the coefficients of are random complex numbers and  , then has no real eigenvalues except for a dominant eigenvalue or zero eigenvalues. In the case when the coefficients of are random real numbers and , the superoperator may have other real eigenvalues, but these non-zero non-dominant eigenvalues will tend to have multiplicity 2.
, then has no real eigenvalues except for a dominant eigenvalue or zero eigenvalues. In the case when the coefficients of are random real numbers and , the superoperator may have other real eigenvalues, but these non-zero non-dominant eigenvalues will tend to have multiplicity 2.
A simple calculation shows that the above observations of the traces of  and of are equivalent.
and of are equivalent.
Observation: The trace of a completely positive superoperator is always a non-negative real number. In particular,  .
.
Observation: Suppose that  are real or complex matrices. Then
are real or complex matrices. Then
 .
.
Therefore  if and only if
if and only if  whenever
whenever  .
.
LSRDRs of homogeneous non-commutative polynomials are typically well behaved even when the polynomial is of a very high degree. For example, let  and let
and let  be a system of non-commutative polynomials each of degree
be a system of non-commutative polynomials each of degree  . Then for
. Then for  , let
, let  . Let
. Let  . Then there are homogeneous non-commutative polynomials
. Then there are homogeneous non-commutative polynomials  where
where  . If are -SRDR of
. If are -SRDR of  trained with different initializations, then we may typically find a central scalar and some invertible
trained with different initializations, then we may typically find a central scalar and some invertible 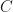 with for . This is despite the fact that has degree
with for . This is despite the fact that has degree  which could be very large.
which could be very large.
One can use LSRDRs to map tensors in  to other objects in several ways. Let
to other objects in several ways. Let  . Then since
. Then since  , we may consider a tensor in as an element of
, we may consider a tensor in as an element of  , and we may take our LSRDR of the tensor
, and we may take our LSRDR of the tensor  Suppose that
Suppose that  . Then we can represent a tensor
. Then we can represent a tensor  as a homogeneous non-commutative polynomial
as a homogeneous non-commutative polynomial  consisting of a linear combination of monomials of the form
consisting of a linear combination of monomials of the form  . Define a fitness function
. Define a fitness function  by setting
by setting 

 where is some mean. Then the fitness function empirically has a unique local maximum value.
where is some mean. Then the fitness function empirically has a unique local maximum value.
Tensors to collections of matrices
Not only are we able to obtain tuples of matrices from tensors, but we may also obtain tensors from tuples of matrices, and go back and forth between tensors and tuples of matrices. Suppose that 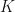 is either the field of real numbers or the field of complex numbers. Let
is either the field of real numbers or the field of complex numbers. Let  . Then a LSRDR
. Then a LSRDR  of
of  is typically unique up to a scalar multiple, and if is the field of complex numbers but each
is typically unique up to a scalar multiple, and if is the field of complex numbers but each  is a real matrix, then
is a real matrix, then  is a real tensor multiplied by a complex nonzero scalar.
is a real tensor multiplied by a complex nonzero scalar.
Suppose that  are finite dimensional inner product spaces over the field . Suppose that
are finite dimensional inner product spaces over the field . Suppose that  is a basis for
is a basis for  . Let
. Let  be a sequence of positive integers with
be a sequence of positive integers with  . Suppose that is an
. Suppose that is an  matrix over the field whenever
matrix over the field whenever  . Then define the tensor
. Then define the tensor  . If
. If 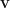 and
and  is locally minimized and
is locally minimized and  , then we say that
, then we say that  is a matrix table to tensor dimensionality reduction of type . Our computer experiments suggest that the matrix table to tensor dimensionality reduction of type is generally unique. Furthermore, if
is a matrix table to tensor dimensionality reduction of type . Our computer experiments suggest that the matrix table to tensor dimensionality reduction of type is generally unique. Furthermore, if  and is an
and is an  -linear combination of the basis vectors
-linear combination of the basis vectors  , then in our computer experiments, the matrix table to tensor dimensionality reduction of type is also an -linear combination of the basis vectors .
, then in our computer experiments, the matrix table to tensor dimensionality reduction of type is also an -linear combination of the basis vectors .
Suppose that is a sparse tensor whose entries are integers and  . Suppose furthermore that
. Suppose furthermore that  are matrix table to tensor dimensionality reductions of \. Then the values
are matrix table to tensor dimensionality reductions of \. Then the values  are often positive integers. It is sometimes but not always the case that each entry in
are often positive integers. It is sometimes but not always the case that each entry in  is an integer or at least a rational number. It is sometimes the case that
is an integer or at least a rational number. It is sometimes the case that
- there is a partition
 of
of  where
where  precisely when
precisely when  ,
,
 is always a positive integer,
is always a positive integer,- there is a positive integer where
 whenever
whenever  ,
,
- if
 , then all of the entries in are integers,
, then all of the entries in are integers,
- if
 , then most but not all of the entries in are integers,
, then most but not all of the entries in are integers,
- if , then the tensor has repeated non-integer entries, and
- one can find non-integer entries
 in where
in where  is a non-zero integer.
is a non-zero integer.
Suppose that is a random tensor in . Then one can often find a matrix table to tensor dimensionality reduction of type such that  is its own matrix table to tensor dimensionality reduction of type .
is its own matrix table to tensor dimensionality reduction of type .
LSRDRs to learn data
LSRDRs may be adapted to solve classification tasks. Suppose that .
Suppose that  are natural numbers. Suppose that
are natural numbers. Suppose that  . Let
. Let  be natural numbers. Suppose that
be natural numbers. Suppose that  for
for  . We say that a collection
. We say that a collection  of matrices is an -spectral radius similarity log-expected maximizer (LSRSLEM) of degree and dimension if locally maximizes the fitness
of matrices is an -spectral radius similarity log-expected maximizer (LSRSLEM) of degree and dimension if locally maximizes the fitness


Application: LSRSLEMs may be used to solve machine learning classification problems. Suppose that 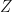 is a universal set. Suppose that we are given a training data set
is a universal set. Suppose that we are given a training data set  , and we would like the machine learning algorithm to recognize objects that are similar to the elements in
, and we would like the machine learning algorithm to recognize objects that are similar to the elements in  . Then one would first construct a function
. Then one would first construct a function  . One then constructs an LSRSLEM of
. One then constructs an LSRSLEM of  Then a higher value of
Then a higher value of  indicates that the value
indicates that the value  is more similar to the training data set .
is more similar to the training data set .
Observation: If each is nearly positive semidefinite, and are LSRSLEMs of the same degree and dimension of  , then typically have the same fitness level.
, then typically have the same fitness level.
Observation: Suppose that is an LSRSLEM. Then one can typically find subspaces  of the vector space such that each
of the vector space such that each  is invariant with respect to each
is invariant with respect to each  and each
and each  . In other words, there is a unitary matrix along with
. In other words, there is a unitary matrix along with  with
with  and where each
and where each  is a block diagonal matrix whose diagonal blocks are matrices
is a block diagonal matrix whose diagonal blocks are matrices  of sizes . Furthermore, the matrices
of sizes . Furthermore, the matrices  typically generate the algebra
typically generate the algebra  .
.
Application: LSRSLEMs may be used to recognize objects in a data set, but LSRSLEMs may also be used to partition data sets into clusters and produce representatives of these clusters. Suppose that is an LSRDLEM of  and each is a block diagonal matrix with block diagonal entries .
and each is a block diagonal matrix with block diagonal entries .
Our clustering function  will simply be the function that maximizes the quantity
will simply be the function that maximizes the quantity  Our clustering function can be used to assign tuples that are not contained in our original
Our clustering function can be used to assign tuples that are not contained in our original  data values to these clusters. Our extended clustering function
data values to these clusters. Our extended clustering function  will be the partial function where if
will be the partial function where if  , then
, then  whenever
whenever  is maximized.
is maximized.
An LSRDR of a cluster  is a representative for the
is a representative for the  -th cluster.
-th cluster.
Iterated LSRSLEM clustering
One can use iterated LSRSLEMs to partition data into clusters. For simplicity, assume that  .
.
Suppose that  is a random positive real number for
is a random positive real number for  . Let
. Let 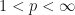 . Then we shall construct
. Then we shall construct  whenever
whenever  using recursion on .
using recursion on .
From  , we construct an LSRSLEM
, we construct an LSRSLEM  of of degree and dimension . Suppose that
of of degree and dimension . Suppose that  is a dominant eigenvector with norm of
is a dominant eigenvector with norm of  whenever
whenever  . Then there is an equivalence relation on
. Then there is an equivalence relation on  where for all
where for all 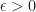 , there is some
, there is some  where if
where if  and
and  , then
, then  whenever
whenever  and
and  otherwise. The equivalence relation does not typically depend on the choices made when training the LSRSLEM for .
otherwise. The equivalence relation does not typically depend on the choices made when training the LSRSLEM for .
The stability of the iterations also suggests that our method of iterating LSRSLEMs will not be able to replicate the capabilities of deep neural networks.
Multiple tensors
Compositional LSRDRs
Suppose that  are positive integers. Suppose that is an
are positive integers. Suppose that is an  -matrix over the field (here addition is taken modulo
-matrix over the field (here addition is taken modulo 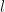 ) whenever
) whenever  . Then we say that
. Then we say that  is a compositional LSRDR (abbreviated CLSRDR) of with dimensions
is a compositional LSRDR (abbreviated CLSRDR) of with dimensions  of if the following quantity known as the fitness is locally maximized:
of if the following quantity known as the fitness is locally maximized:

Observation: Two CLSRDRs of often have the same fitness levels.
Observation: Suppose that  are positive integers with
are positive integers with  for all . Then a CLSRDR with dimensions will typically have the same fitness level as a CLSRDR with dimensions
for all . Then a CLSRDR with dimensions will typically have the same fitness level as a CLSRDR with dimensions  .
.
Observation: Suppose that  is a CLSRDR of . Then one can often find two sequences
is a CLSRDR of . Then one can often find two sequences  of matrices where
of matrices where  for all
for all  . Furthermore, for all , there is a non-zero constant where
. Furthermore, for all , there is a non-zero constant where  . We say that the CLSRDR is constant factor normalized if
. We say that the CLSRDR is constant factor normalized if  for all . In this case, the matrix
for all . In this case, the matrix  will be a projection matrix that we may denote by
will be a projection matrix that we may denote by 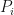 .
.
Let  denote the matrices where
denote the matrices where  is the dominant eigenvector of
is the dominant eigenvector of  and where
and where  is the dominant eigenvector of the adjoint
is the dominant eigenvector of the adjoint  . Then the matrices
. Then the matrices  are generally positive semidefinite up to a constant factor. If we train the CLSRDR twice then each time we will get the same value for
are generally positive semidefinite up to a constant factor. If we train the CLSRDR twice then each time we will get the same value for  .
.
Suppose furthermore that  for all . Then
for all . Then  whenever the CLSRDR is constant factor normalized, and the positive semidefinite matrices do not depend on the value .
whenever the CLSRDR is constant factor normalized, and the positive semidefinite matrices do not depend on the value .
WHAT IF ALL BUT ONE ENTRY IS ZERO? BLOCK MATRICES. UNDER CONSTRUCTION. Suppose that 
Other fitness functions
Let  be a finite dimensional real or complex inner product space. Suppose that is a Borel probability measure with compact support on
be a finite dimensional real or complex inner product space. Suppose that is a Borel probability measure with compact support on 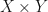 . Now define a fitness function
. Now define a fitness function  by letting
by letting 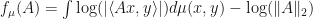 .
.
If  is a Borel probability measure with compact support on , then define a fitness function
is a Borel probability measure with compact support on , then define a fitness function 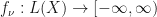 by letting
by letting 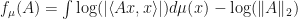 .
.
If are real inner product spaces, then 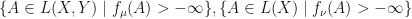 will generally be disconnected spaces, so gradient ascent will have no hope of finding an
will generally be disconnected spaces, so gradient ascent will have no hope of finding an  or
or 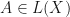 that maximizes
that maximizes  respectively simply by using gradient ascent with a random initialization. However,
respectively simply by using gradient ascent with a random initialization. However, 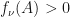 whenever is positive definite, and gradient ascent seems to always produce the same local optimum value
whenever is positive definite, and gradient ascent seems to always produce the same local optimum value  for the function
for the function  when is initialized to be a positive semidefinite matrix. If are linear operators that maximize , then we generally have
when is initialized to be a positive semidefinite matrix. If are linear operators that maximize , then we generally have 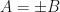 .
.
If is a complex inner product space, then gradient ascent seems to always produce the same local optimal value for the fitness function , and if are matrices that maximize the fitness function , then we generally have  for some . The local optimal operator
for some . The local optimal operator 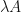 will generally have positive eigenvalues for some , but the operator itself will not be positive semidefinite. If
will generally have positive eigenvalues for some , but the operator itself will not be positive semidefinite. If 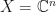 and is supported on , then for each operator that optimizes , there is some where
and is supported on , then for each operator that optimizes , there is some where ![\lambda A[\mathbb{R}^n]\subseteq\mathbb{R}^n](https://s0.wp.com/latex.php?latex=%5Clambda+A%5B%5Cmathbb%7BR%7D%5En%5D%5Csubseteq%5Cmathbb%7BR%7D%5En&bg=ffffff&fg=111111&s=0&c=20201002) , and is up to sign the same matrix found by real gradient ascent with positive definite initialization.
, and is up to sign the same matrix found by real gradient ascent with positive definite initialization.
The problem of optimizing is a problem that is useful for constructing MPO word embeddings and other objects for machine learning similar to LSRDR dimensionality reductions. While tends to have a unique up to constant factor local optimum, the fitness function 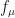 does not generally have a unique local optimum; if are complex inner product spaces, then has few local optima in the sense that it is not unusual to there to be a constant where such that locally optimize . In this case, the matrix that globally optimizes is most likely also the matrix that has the largest basin of attraction with respect to various types of gradient ascent.
does not generally have a unique local optimum; if are complex inner product spaces, then has few local optima in the sense that it is not unusual to there to be a constant where such that locally optimize . In this case, the matrix that globally optimizes is most likely also the matrix that has the largest basin of attraction with respect to various types of gradient ascent.
MPO word embeddings: Suppose that is a matrix embedding potential, is a finite set, and  . Suppose that
. Suppose that  is are MPO word pre-embeddings with respect to the matrix embedding potential . Then there are often constants
is are MPO word pre-embeddings with respect to the matrix embedding potential . Then there are often constants 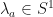 for
for 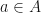 where
where  for . Furthermore, there is often a matrix
for . Furthermore, there is often a matrix 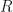 along with constants
along with constants  for where
for where  is a real matrix for .
is a real matrix for .
Rank-1 matrix valued graph embeddings
Applying pseudodeterminism to test randomness/pseudorandomness
The uniqueness of the fitness functions (pseudodeterminism) in the machine learning algorithms in this post is useful for testing for randomness/pseudorandomness in cryptography. Here is a non-exhaustive list of ways that one can use pseudodeterministic machine learning algorithms to test data sets for randomness/pseudorandomness and to measure the quantity of randomness/pseudorandomness in the data set and obtain confidence levels of the non-randomness/pseudorandomness of an object.
Application: Let be a finite set. Let and let be a positive integer. Let  . Define our fitness function
. Define our fitness function  by setting
by setting  If
If  is locally maximized, then a lower value of indicates that the sequence
is locally maximized, then a lower value of indicates that the sequence  is more random/pseudorandom.
is more random/pseudorandom.
Application: Suppose that is a finite set, is a natural number, and  is a subset. Let and let be a positive integer. Define a function
is a subset. Let and let be a positive integer. Define a function  by setting
by setting 
 .
.
If is locally maximized, then a lower value of indicates that the set is more random/pseudorandom.
Best quantum channel approximation to a relation.
Let 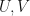 be complex Euclidean spaces. Suppose that
be complex Euclidean spaces. Suppose that  be such that each
be such that each 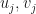 is a unit vector. Then we say that a quantum channel
is a unit vector. Then we say that a quantum channel  is a best Choi rank
is a best Choi rank  approximation to
approximation to 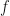 if the quantity
if the quantity  is locally minimized subject to the condition that is a quantum channel of Choi rank at most .
is locally minimized subject to the condition that is a quantum channel of Choi rank at most .
Empirical observation: Best Choi rank approximations to functions tend to be unique in the sense that the gradient descent process tends to produce the same Best Choi rank approximations when we run the gradient descent multiple times.
Suppose that is a best Choi rank approximation to  .
.
Let where each is a unit vector. For each , let  be a unit dominant eigenvector of
be a unit dominant eigenvector of  . Let
. Let  . Then we typically have
. Then we typically have  . More generally, if is a neighborhood of
. More generally, if is a neighborhood of  of small diameter and
of small diameter and  , then we typically have
, then we typically have  and if is a best Choi rank -approximation to
and if is a best Choi rank -approximation to  , then is typically the identity mapping.
, then is typically the identity mapping.
Afterward
Even though I have published this post, this post is not yet complete since I would like to add information to this post about functions related to and which satisfy similar properties to the functions of the form . I also want the community to actually say something and communicate back before I add any information to this post.
