In this post, we shall discuss the notion of the GMNO hypergraph embedding. This graph/hypergraph embedding is related to the 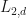 -spectral radii and satisfies similar properties to the -spectral radii, MPO word embeddings, and also embeddings obtained from eigenvectors of the Laplacian matrix of a graph. Even though I have published this post, I will eventually add more details to this post.
-spectral radii and satisfies similar properties to the -spectral radii, MPO word embeddings, and also embeddings obtained from eigenvectors of the Laplacian matrix of a graph. Even though I have published this post, I will eventually add more details to this post.
Suppose that 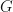 is a graph or hypergraph with unlabeled vertex set
is a graph or hypergraph with unlabeled vertex set  . Let
. Let 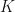 denote the division algebra of the real numbers, complex numbers, or quaternions. Our goal is to be able to construct a function
denote the division algebra of the real numbers, complex numbers, or quaternions. Our goal is to be able to construct a function  for some
for some 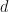 where machine learning models can more easily work with
where machine learning models can more easily work with  for
for 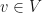 than directly with the elements .
than directly with the elements .
Suppose that is a set which we shall call a vertex set. Let 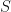 be a collection of functions
be a collection of functions  where
where  and where
and where  for . Let
for . Let ![w:S\rightarrow[0,1]](https://s0.wp.com/latex.php?latex=w%3AS%5Crightarrow%5B0%2C1%5D&bg=ffffff&fg=111111&s=0&c=20201002) be a function such that
be a function such that  . Let
. Let  be a function which we shall call a multiplicity function (or you can call
be a function which we shall call a multiplicity function (or you can call  the vertex weight function). The function
the vertex weight function). The function  shall be called a generalized weighted hypergraph structure on the vertex set .
shall be called a generalized weighted hypergraph structure on the vertex set .
If , then define the fitness of 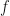 with respect to
with respect to  by
by
 .
.
We say that a function is a geometric mean of norm optimized (GMNO) pre-embedding for the generalized hypergraph structure and multiplicity function if 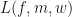 is locally maximized. Here, we have not made any attempt to make the fitness function a very general function.
is locally maximized. Here, we have not made any attempt to make the fitness function a very general function.
We say that a GMNO pre-embedding is a GMNO hypergraph embedding if the matrix 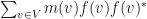 is a diagonal matrix with increasing diagonal entries. If
is a diagonal matrix with increasing diagonal entries. If  , then we say that a GMNO embedding is positive for
, then we say that a GMNO embedding is positive for 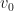 if each entry in
if each entry in  is positive.
is positive.
Observation: 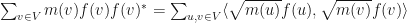 which can easily be interpreted as a quantity of potential energy of the function .
which can easily be interpreted as a quantity of potential energy of the function .
One can define the class so that with an embedding , certain vertices will be far away from each other. If  , and
, and 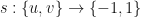 is the function defined by letting
is the function defined by letting  , and
, and 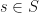 , then indicates that the vertices
, then indicates that the vertices  should be far away from each other.
should be far away from each other.
Desirable properties:
- (Empirical uniqueness of local optimum) The GMNO embedding for a multiplicity function and generalized hypergraph that is positive for with
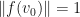 is typically unique. If
is typically unique. If  and
and  are GMNO embeddings with
are GMNO embeddings with 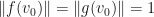 which are both positive for , and
which are both positive for , and  have both been obtained using gradient ascent but with possibly different initial conditions and different optimizers, then we typically have
have both been obtained using gradient ascent but with possibly different initial conditions and different optimizers, then we typically have  . By training the GMNO embedding twice and obtaining GMNO embeddings , one can test whether the GMNO embedding is satisfactory or not; the GMNO embeddings are likely to be satisfactory precisely when .
. By training the GMNO embedding twice and obtaining GMNO embeddings , one can test whether the GMNO embedding is satisfactory or not; the GMNO embeddings are likely to be satisfactory precisely when .
2. (Learned realization) Suppose that  . Then for a GMNO embedding that is positive for some , we typically have
. Then for a GMNO embedding that is positive for some , we typically have ![f[V]\subseteq\mathbb{R}^d](https://s0.wp.com/latex.php?latex=f%5BV%5D%5Csubseteq%5Cmathbb%7BR%7D%5Ed&bg=ffffff&fg=111111&s=0&c=20201002) . One can test whether a GMNO embedding is satisfactory by training the embedding when . The GMNO embedding is likely to be satisfactory precisely when .
. One can test whether a GMNO embedding is satisfactory by training the embedding when . The GMNO embedding is likely to be satisfactory precisely when .
3. (Sphericity) If  is a GMNO embedding for a suitable multiplicity function and generalized hypergraph , then
is a GMNO embedding for a suitable multiplicity function and generalized hypergraph , then 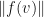 will typically have very low variance. In particular, if
will typically have very low variance. In particular, if ![E[\|f(v)\|]\approx 1](https://s0.wp.com/latex.php?latex=E%5B%5C%7Cf%28v%29%5C%7C%5D%5Capprox+1&bg=ffffff&fg=111111&s=0&c=20201002) , then
, then ![f[V]](https://s0.wp.com/latex.php?latex=f%5BV%5D&bg=ffffff&fg=111111&s=0&c=20201002) will typically be near the sphere
will typically be near the sphere 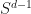 . One can train the multiplicity function while simultaneously training the GMNO embedding so that
. One can train the multiplicity function while simultaneously training the GMNO embedding so that ![f[V]\subseteq S^{d-1}](https://s0.wp.com/latex.php?latex=f%5BV%5D%5Csubseteq+S%5E%7Bd-1%7D&bg=ffffff&fg=111111&s=0&c=20201002) when is a fully trained GMNO embedding.
when is a fully trained GMNO embedding.
4. (Thin singularities) While the fitness function  does have singularities, these singularities have a small dimension and high codimension (all but one of the singularities has codimension ). The singularities of the fitness function are unlikely to cause any issues.
does have singularities, these singularities have a small dimension and high codimension (all but one of the singularities has codimension ). The singularities of the fitness function are unlikely to cause any issues.
5. (Interpretability) It is not to difficult to see relations between a hypergraph and its corresponding GMNO embedding . For example, from a GMNO embedding , one can easily identify clusters, intersecting clusters, and much of the geometric structure of the hypergraph  .
.
6. (Improved performance in high dimensions) By increasing the dimension , one can produce a higher quality GMNO embedding. For example, the empirical uniqueness of local optimum and learned realization properties are often satisfied only when is sufficiently large.
7. (Fast gradient computation) The gradient of with respect to is easy to compute.
8. (Adaptability) GMNO embeddings are reasonable graph embeddings for many different kinds of graphs including graphs with a very high diameter to order ratio, graphs with several (intersecting or non-intersecting) clusters, and graphs with a low diameter but high clustering coefficient.
Other properties: GMNO hypergraph embeddings also satisfy properties that may or may not be desirable.
- (Uncentered) If
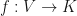 is a GMNO embedding, then the expected value
is a GMNO embedding, then the expected value 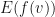 is typically far away from the origin
is typically far away from the origin 
- (Dimension filling) In order to minimize , the matrix will tend to be close to a constant multiple of the identity matrix. In other words, the function will often (but not always) use all available dimensions nearly equally. This may result in a high dimensional GMNO embedding even when
 is inherently low dimensional. This problem can be ameliorated by reducing the dimension or by generalizing the notion of a GMNO embedding. There are cases (including positional embeddings) where one would want to embed a low dimensional graph into a high dimensional space.
is inherently low dimensional. This problem can be ameliorated by reducing the dimension or by generalizing the notion of a GMNO embedding. There are cases (including positional embeddings) where one would want to embed a low dimensional graph into a high dimensional space.
- (Flat embedding) Sometimes the matrix can be well approximated by a low rank matrix. This means that not all dimensions in
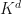 are used equally. The notion of a GMNO hypergraph embedding can be generalized so that the dimensions of are used more evenly.
are used equally. The notion of a GMNO hypergraph embedding can be generalized so that the dimensions of are used more evenly.
- (Weak repulsion) For GMNO hypergraph embeddings, it is possible that there are unrelated where
 and are very close together. This problem can be ameliorated by increasing the dimension , so if is sufficiently large, it will be unlikely to have near unless the vertices are related.
and are very close together. This problem can be ameliorated by increasing the dimension , so if is sufficiently large, it will be unlikely to have near unless the vertices are related.
- (Homophilicity) GMNO hypergraph embeddings are not good for predicting links between nodes that are dissimilar form each other. For example, in a bipartite graph with bipartition
 each edge must connect one block of the partition to the other block, but the GMNO hypergraph embedding will not have any way of knowing that the nodes in
each edge must connect one block of the partition to the other block, but the GMNO hypergraph embedding will not have any way of knowing that the nodes in  should not be connected to different nodes in .
should not be connected to different nodes in .
Comparison with spectral clustering: GMNO hypergraph embeddings are closely related to the eigenvalues of the Laplacian matrix of a graph for a few reasons. First of all, the eigenvalues of the Laplacian are always unique while the GMNO hypergraph embeddings are often unique. There is also a loss function resembling the loss function where the input that minimizes this loss function is simply the bottom -non-zero eigenvectors of the Laplacian matrix.
A potential application: positional embeddings GMNO hypergraph embeddings can be used to produce positional embeddings for convolutional neural networks. For example, one can represent a 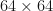 grid as a hypergraph. One can also add additional hyperedges to this hypergraph that represent regions in images that the CNN is training on. Suppose that
grid as a hypergraph. One can also add additional hyperedges to this hypergraph that represent regions in images that the CNN is training on. Suppose that  is a GMNO embedding with respect to this hypergraph. Define
is a GMNO embedding with respect to this hypergraph. Define  by letting
by letting  . Then a positional embedding layer is a function
. Then a positional embedding layer is a function  defined by letting
defined by letting  . By including a positional embedding layer in a CNN, the network has not only information about the content of the image but the location of that content as well. We recommend using GMNO embedding for this positional embedding layer and using a positional embedding layer in CNNs (of course, it may be easier to add the positional information simply by training the CNN, so one may want to do experiments on this).
. By including a positional embedding layer in a CNN, the network has not only information about the content of the image but the location of that content as well. We recommend using GMNO embedding for this positional embedding layer and using a positional embedding layer in CNNs (of course, it may be easier to add the positional information simply by training the CNN, so one may want to do experiments on this).
Embeddings from generalized means
Suppose that is a generalized weighted hypergraph structure on a vertex set and  is a multiplicity function. Let
is a multiplicity function. Let  be a weighted mean function (for example, could denote the weighted $p$-mean for some non-zero real number
be a weighted mean function (for example, could denote the weighted $p$-mean for some non-zero real number  ). Let
). Let  be a continuous function such that
be a continuous function such that  whenever
whenever  .
.
Then define 
Then if maximizes  , we say that is an MNO (mean of norm optimized)-hypergraph pre-embedding. If also the matrix is a diagonal matrix with increasing diagonal entries, then we say that is an MNO hypergraph embedding. If each entry in is positive, then we say that is positive for .
, we say that is an MNO (mean of norm optimized)-hypergraph pre-embedding. If also the matrix is a diagonal matrix with increasing diagonal entries, then we say that is an MNO hypergraph embedding. If each entry in is positive, then we say that is positive for .
Even though I have published this post, I will add more details onto this post later.
