In this post, we will not talk about cryptography, but we will talk about another application and generalization of the 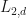 -spectral radius to producing word embeddings and graph embeddings for machine learning applications. We shall call these word embeddings matrix product optimized (MPO) word embeddings. These MPO word embeddings and graph embeddings do not require any neural networks to produce at the moment, but once these word and graph embeddings are produced, they can be processed using neural networks. Even though the MPO word embeddings are not produced using neural networks, they have features and advantages that no other word embedding algorithm currently has. For example, MPO word embeddings can be used to evaluate the local grammatical correctness of text and produce text with the help of evolutionary computation or simulated annealing. MPO word embeddings are also the only kind of word embedding that we know of that map words to matrices, and matrix-valued word embeddings enjoy plenty of advantages over vector-valued word embeddings. MPO word embeddings also behave much more mathematically than other word embedding algorithms; for example, even when training an MPO word embedding over the field of complex numbers, the resulting word embedding (if everything goes right) will be a real matrix valued function. MPO word embeddings also also more consistent in the sense that the resulting MPO word embedding does not depend on the initialization. Any initialization would converge to a nearby MPO word embedding.
-spectral radius to producing word embeddings and graph embeddings for machine learning applications. We shall call these word embeddings matrix product optimized (MPO) word embeddings. These MPO word embeddings and graph embeddings do not require any neural networks to produce at the moment, but once these word and graph embeddings are produced, they can be processed using neural networks. Even though the MPO word embeddings are not produced using neural networks, they have features and advantages that no other word embedding algorithm currently has. For example, MPO word embeddings can be used to evaluate the local grammatical correctness of text and produce text with the help of evolutionary computation or simulated annealing. MPO word embeddings are also the only kind of word embedding that we know of that map words to matrices, and matrix-valued word embeddings enjoy plenty of advantages over vector-valued word embeddings. MPO word embeddings also behave much more mathematically than other word embedding algorithms; for example, even when training an MPO word embedding over the field of complex numbers, the resulting word embedding (if everything goes right) will be a real matrix valued function. MPO word embeddings also also more consistent in the sense that the resulting MPO word embedding does not depend on the initialization. Any initialization would converge to a nearby MPO word embedding.
In artificial intelligence, and more specifically, natural language processing (NLP), one would want to convert words, characters, punctuation, or other tokens into something that computers can work with such as vectors in a vector space. A word embedding is typically a function from a set of tokens  to a finite dimensional real vector space
to a finite dimensional real vector space  . With a word embedding, AI systems will therefore be able to process vectors rather than text, but we may be able to improve upon the idea of mapping tokens to elements in a vector space by instead mapping tokens to real or complex matrices. Spaces of real or complex matrices have more structure than simply vector spaces since spaces of matrices are equipped with matrix multiplication, the Frobenius inner product, several orthogonal or unitary invariant submultiplicative norms, many matrix decompositions such as the singular value decomposition, et cetera, and we shall see that this additional structure of
. With a word embedding, AI systems will therefore be able to process vectors rather than text, but we may be able to improve upon the idea of mapping tokens to elements in a vector space by instead mapping tokens to real or complex matrices. Spaces of real or complex matrices have more structure than simply vector spaces since spaces of matrices are equipped with matrix multiplication, the Frobenius inner product, several orthogonal or unitary invariant submultiplicative norms, many matrix decompositions such as the singular value decomposition, et cetera, and we shall see that this additional structure of 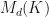 is very useful for word embeddings in NLP. Matrix multiplication can also be exploited by matrix neural networks [GGW] which are neural networks whose layers are of the form
is very useful for word embeddings in NLP. Matrix multiplication can also be exploited by matrix neural networks [GGW] which are neural networks whose layers are of the form  where
where 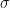 is an elementwise activation function and
is an elementwise activation function and 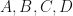 are learnable matrices of the appropriate dimensions.
are learnable matrices of the appropriate dimensions.
Since tokens in natural language often have multiple related and unrelated meanings, a word embedding should be designed so that these meanings can be easily distinguished from each other. While vectors are suitable for encoding a single meaning of a token, matrices are much better suited for encoding multiple meanings of a token since each row (or column) of a matrix could represent a particular meaning of the word.
Suppose that 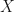 is real or complex matrix. Then by applying a singular value decomposition, we obtain
is real or complex matrix. Then by applying a singular value decomposition, we obtain 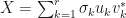 where
where 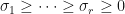 are the singular values of , and
are the singular values of , and  are two orthonormal bases. As usual, the matrix could represent a token while each rank-1 matrix
are two orthonormal bases. As usual, the matrix could represent a token while each rank-1 matrix  could represent a specific meaning of the token and the singular values
could represent a specific meaning of the token and the singular values  represent the prevalence of such a meaning of the token. We observe that with MPO word embeddings, the singular value decomposition does indeed decompose a matrix representing words into a sum of rank-1 matrices each representing a specific meaning of the word.
represent the prevalence of such a meaning of the token. We observe that with MPO word embeddings, the singular value decomposition does indeed decompose a matrix representing words into a sum of rank-1 matrices each representing a specific meaning of the word.
Now assume that is an 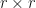 -positive semidefinite matrix. Then the singular value decomposition reduces to the the spectral theorem, and we have
-positive semidefinite matrix. Then the singular value decomposition reduces to the the spectral theorem, and we have  for all
for all  , and we can write
, and we can write 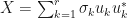 where are the singular values of . In this case, could represent a token while each vector
where are the singular values of . In this case, could represent a token while each vector  could represent an orthogonal meaning of the token while
could represent an orthogonal meaning of the token while  represents the prevalence of this meaning. In terms of quantum information theory, a token is represented by a mixed state while the specific meanings of the token are represented as pure states, so the token is a superposition of all of its possible meanings.
represents the prevalence of this meaning. In terms of quantum information theory, a token is represented by a mixed state while the specific meanings of the token are represented as pure states, so the token is a superposition of all of its possible meanings.
In this post, will be a set that represents the set of all tokens, and 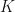 denotes either the field of real or complex numbers. If
denotes either the field of real or complex numbers. If  is a function, then define
is a function, then define  by letting
by letting  whenever
whenever 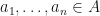 .
.
The general idea behind MPO word embeddings is that given a string  over the alphabet (the string is the corpus that the MPO word embedding trains with) and a natural number
over the alphabet (the string is the corpus that the MPO word embedding trains with) and a natural number 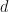 , our MPO word embedding of shall be a function that maximizes the product
, our MPO word embedding of shall be a function that maximizes the product  . Since one can make arbitrarily large by increasing the value of
. Since one can make arbitrarily large by increasing the value of 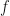 , we need to normalize the quantity . We therefore want for the MPO word embeddings to maximize an expression that looks like
, we need to normalize the quantity . We therefore want for the MPO word embeddings to maximize an expression that looks like 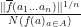 . The function
. The function  should be defined so that is bounded and cannot be optimized simply by making large. The function
should be defined so that is bounded and cannot be optimized simply by making large. The function  needs to be also designed so that in a trained MPO word embedding, the matrices
needs to be also designed so that in a trained MPO word embedding, the matrices 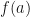 will be sufficiently far away from each other. In other words, if the matrices are similar to each other, then the denominator
will be sufficiently far away from each other. In other words, if the matrices are similar to each other, then the denominator  should be large, but if the matrices are distributed evenly, then the value
should be large, but if the matrices are distributed evenly, then the value  should be small. In a trained MPO word embedding, since the matrices are sufficiently far away from each other and relatively small and since relatively large, the value must be as large as possible, so the matrices
should be small. In a trained MPO word embedding, since the matrices are sufficiently far away from each other and relatively small and since relatively large, the value must be as large as possible, so the matrices  need to be compatible with its neighboring matrices.
need to be compatible with its neighboring matrices.
To illustrate how the size of the matrix product  equates with the compatibility of each of the matrices
equates with the compatibility of each of the matrices  with its neighboring matrices, suppose that are rank-1 matrices so that for all
with its neighboring matrices, suppose that are rank-1 matrices so that for all 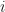 , we have a factorization
, we have a factorization  for some
for some  . Then
. Then  . Therefore,
. Therefore,  if and only if for each , there is some
if and only if for each , there is some  where
where 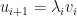 where addition is taken modulo
where addition is taken modulo  . Furthermore,
. Furthermore, 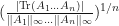 is a measure of compatibility between the matrices of the form
is a measure of compatibility between the matrices of the form  and its neighboring matrices.
and its neighboring matrices.
We say that a function  is a matrix embedding potential if whenever
is a matrix embedding potential if whenever  , we have
, we have
 for each permutation ,
for each permutation ,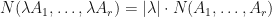 whenever
whenever  ,
, whenever
whenever  and
and  is unitary or
is unitary or  and is orthogonal, and
and is orthogonal, and- there is some
 where if
where if 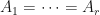 , then
, then 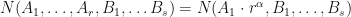 . The constant shall be called the amplification degree.
. The constant shall be called the amplification degree.
If  , then define the superoperator
, then define the superoperator  by letting
by letting  . We say that a matrix embedding potential is superoperator invariant if
. We say that a matrix embedding potential is superoperator invariant if  whenever
whenever  We say that a matrix embedding potential is torus invariant if
We say that a matrix embedding potential is torus invariant if 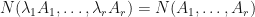 whenever
whenever 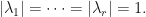 For example, every superoperator invariant matrix embedding potential is also torus invariant. We say that a matrix embedding potential
For example, every superoperator invariant matrix embedding potential is also torus invariant. We say that a matrix embedding potential 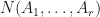 is a polarizer if it is not torus invariant.
is a polarizer if it is not torus invariant.
Recall that  denotes the spectral radius of and
denotes the spectral radius of and 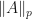 denotes the Schatten
denotes the Schatten  -norm of .
-norm of .
We have the following examples of matrix embedding potentials:
Example 0: 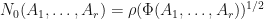 is a superoperator invariant matrix embedding potential.
is a superoperator invariant matrix embedding potential.
Example 1: 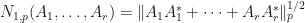 is another example of a torus invariant matrix embedding potential for
is another example of a torus invariant matrix embedding potential for  (we should choose
(we should choose 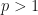 to ensure that the MPO word embedding is not a constant function).
to ensure that the MPO word embedding is not a constant function).
Example 2:  is a torus invariant matrix embedding potential whenever and
is a torus invariant matrix embedding potential whenever and  . As before, for MPO word embeddings, we must select to ensure that the matrix embedding potential is not a constant function.
. As before, for MPO word embeddings, we must select to ensure that the matrix embedding potential is not a constant function.
Example 3:  is a torus invariant matrix embedding potential whenever and . We will leave it to the reader to generalize this example to obtain other torus invariant matrix embedding potentials.
is a torus invariant matrix embedding potential whenever and . We will leave it to the reader to generalize this example to obtain other torus invariant matrix embedding potentials.
Example 4: 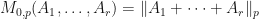 is a polarizer for .
is a polarizer for .
Example 5:  is a polarizer.
is a polarizer.
If is a matrix embedding potential,  , and is a function, then define
, and is a function, then define  and define
and define 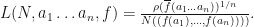 We observe that if
We observe that if  , then
, then  can be approximated with the expression
can be approximated with the expression 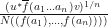 or with
or with  for any matrix norm
for any matrix norm 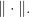
We say that a function is an amplified MPO word pre-embedding for the matrix embedding potential and corpus if the quantity  is a local maximum with respect to the function . We say that is a normalized MPO word pre-embedding for and if the quantity is a local maximum with respect to the function . Let
is a local maximum with respect to the function . We say that is a normalized MPO word pre-embedding for and if the quantity is a local maximum with respect to the function . Let  denote the amplification degree of the matrix embedding potential . Suppose that the token
denote the amplification degree of the matrix embedding potential . Suppose that the token  appears
appears  times in the string and
times in the string and 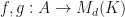 are functions such that
are functions such that 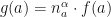 for
for 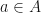 . Then
. Then  is an amplified MPO word pre-embedding if and only if is a normalized MPO word pre-embedding for and . Unless otherwise specified, we shall assume that each MPO word pre-embedding is a normalized MPO word pre-embedding.
is an amplified MPO word pre-embedding if and only if is a normalized MPO word pre-embedding for and . Unless otherwise specified, we shall assume that each MPO word pre-embedding is a normalized MPO word pre-embedding.
A final rotation–
Suppose that are functions and is an MPO word pre-embeddings for the matrix embedding potential and corpus , and there are constants  with
with  for . Then will also be an MPO word pre-embedding. We may therefore select the free parameters for optimal performance.
for . Then will also be an MPO word pre-embedding. We may therefore select the free parameters for optimal performance.
A naive approach to selecting these parameters  would be to select some select some invariant
would be to select some select some invariant 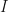 (like the trace or determinant) such that
(like the trace or determinant) such that 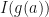 is a real number for all . Since the matrices
is a real number for all . Since the matrices  can be approximated by matrices of a low rank, we should not let be the determinant. We do not recommend simply letting be the trace either because the mapping
can be approximated by matrices of a low rank, we should not let be the determinant. We do not recommend simply letting be the trace either because the mapping  has a singularity of high dimension. In fact, the union of the zero set of with the set of points where
has a singularity of high dimension. In fact, the union of the zero set of with the set of points where  is discontinuous is always has large dimension, so the function
is discontinuous is always has large dimension, so the function  always has a large singularity. If
always has a large singularity. If 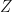 is a subset of
is a subset of  and
and  is a continuous function where
is a continuous function where ![\iota([x])=x](https://s0.wp.com/latex.php?latex=%5Ciota%28%5Bx%5D%29%3Dx&bg=ffffff&fg=111111&s=0&c=20201002) or
or ![\iota([x])=-x](https://s0.wp.com/latex.php?latex=%5Ciota%28%5Bx%5D%29%3D-x&bg=ffffff&fg=111111&s=0&c=20201002) whenever
whenever ![x\in S^n,[x]\in\mathbb{RP}^n\setminus Z](https://s0.wp.com/latex.php?latex=x%5Cin+S%5En%2C%5Bx%5D%5Cin%5Cmathbb%7BRP%7D%5En%5Csetminus+Z&bg=ffffff&fg=111111&s=0&c=20201002) , then must intersect each loop
, then must intersect each loop ![\ell:[0,1]\rightarrow\mathbb{RP}^n](https://s0.wp.com/latex.php?latex=%5Cell%3A%5B0%2C1%5D%5Crightarrow%5Cmathbb%7BRP%7D%5En&bg=ffffff&fg=111111&s=0&c=20201002) with
with  which is not homotopy equivalent to the null loop. In other words, the set is necessarily a large set. One can make a similar observation for the complex projective spaces.
which is not homotopy equivalent to the null loop. In other words, the set is necessarily a large set. One can make a similar observation for the complex projective spaces.
A more reasonable choice would be to select the constants for so that the function maximizes or minimizes some quantity. One disadvantage of this approach is that in order to apply gradient ascent or descent effectively to optimize the fitness of , the field should be the field of complex numbers. Fortunately, if , one can ensure that the sign of  is correct by using a proper initialization, and if , then we shall call any MPO word pre-embedding an MPO word embedding; unfortunately, we are not able to perform this technique when
is correct by using a proper initialization, and if , then we shall call any MPO word pre-embedding an MPO word embedding; unfortunately, we are not able to perform this technique when  .
.
Suppose that and is an MPO word pre-embedding with respect to the matrix embedding potential and corpus . If is a polarizer, then we say that is an MPO word pre-embedding. Suppose now that is torus invariant and  is a polarizer. Let for , and define a mapping
is a polarizer. Let for , and define a mapping 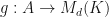 by letting
by letting 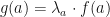 for . Then we say that is an MPO word embedding with respect to the polarizer if
for . Then we say that is an MPO word embedding with respect to the polarizer if  is locally maximized with respect to
is locally maximized with respect to  .
.
The MPO word embeddings with respect to the polarizer  can not only be described as a function that maximizes the norm of the sum, but the word embeddings equivalently minimize the spring energy and maximize the real part of the sum of the dot product. Let be a finite totally ordered set.
can not only be described as a function that maximizes the norm of the sum, but the word embeddings equivalently minimize the spring energy and maximize the real part of the sum of the dot product. Let be a finite totally ordered set.
We observe that  and
and
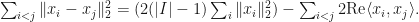
Observation: Let be a finite set. Let 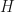 be a complex Hilbert space. Let
be a complex Hilbert space. Let  be the equivalence relation on where we set
be the equivalence relation on where we set  if and only if there is some
if and only if there is some  with
with  and
and 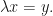 Suppose that
Suppose that 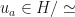 for
for 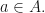 Let
Let 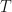 be the collection of all
be the collection of all 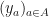 where
where ![[y_a]=u_a](https://s0.wp.com/latex.php?latex=%5By_a%5D%3Du_a&bg=ffffff&fg=111111&s=0&c=20201002) for .
for .
- The norm of the sum
 is locally maximized for
is locally maximized for  .
.
2. The sum 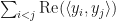 is locally maximized for .
is locally maximized for .
3. The spring energy 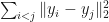 is locally minimized for .
is locally minimized for .
Positive MPO word embeddings-If is an MPO word pre-embedding, then we shall say that the mapping  is a positive MPO word embedding. We observe that if is another MPO word pre-embedding where
is a positive MPO word embedding. We observe that if is another MPO word pre-embedding where  for , then $latex
for , then $latex  . It is therefore easier to train a positive MPO word embedding than to train an MPO word embedding. Since the mapping
. It is therefore easier to train a positive MPO word embedding than to train an MPO word embedding. Since the mapping  is injective almost everywhere, the MPO word pre-embedding can be recovered from the positive MPO word embedding
is injective almost everywhere, the MPO word pre-embedding can be recovered from the positive MPO word embedding  . We believe that machine learning models may have an easier time working with positive MPO word embeddings than with MPO word embeddings.
. We believe that machine learning models may have an easier time working with positive MPO word embeddings than with MPO word embeddings.
Reduced rank– Computer experiments indicate that if is an MPO word embedding, then the matrices of the form can be approximated by matrices of low rank. If we bound the rank of the matrix by some value  where
where  , then we can reduce the amount of computation required to compute an approximate MPO word embedding. To do this, we can set
, then we can reduce the amount of computation required to compute an approximate MPO word embedding. To do this, we can set 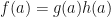 where
where  for and compute the MPO word embedding while only needing to keep
for and compute the MPO word embedding while only needing to keep 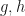 in memory in order to save on computational resources.
in memory in order to save on computational resources.
Basic text generation and evaluation: We say that a string  is locally grammatically correct of window size if
is locally grammatically correct of window size if 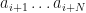 is a a substring of tokens of grammatically correct text whenever
is a a substring of tokens of grammatically correct text whenever 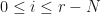 . One can use MPO word embeddings to evaluate whether a string of words is similar to substrings of the corpus and are likely to be locally grammatically correct. By using simulated annealing or evolutionary computation to maximize a coefficient rating the local grammatical correctness, one can automatically generate locally grammatically correct strings and sometimes complete sentences.
. One can use MPO word embeddings to evaluate whether a string of words is similar to substrings of the corpus and are likely to be locally grammatically correct. By using simulated annealing or evolutionary computation to maximize a coefficient rating the local grammatical correctness, one can automatically generate locally grammatically correct strings and sometimes complete sentences.
If is a function, then let  be a submultiplicative orthogonal invariant matrix norm. Then let
be a submultiplicative orthogonal invariant matrix norm. Then let  be the function defined by letting
be the function defined by letting  whenever . Let
whenever . Let  . Then
. Then  is a real number in the interval
is a real number in the interval ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=111111&s=0&c=20201002) . Define
. Define  . Then
. Then  will always be a real number in the interval . If
will always be a real number in the interval . If  , then the string is more likely to be locally grammatically correct text than the string
, then the string is more likely to be locally grammatically correct text than the string  . One can use techniques such as simulated annealing to maximize and when is maximized, the string
. One can use techniques such as simulated annealing to maximize and when is maximized, the string  will resemble grammatically correct text. We will leave it to the reader to figure out how neural networks trained to produce the CBOW word embedding may be used to evaluate the local grammatical correctness of text. It should therefore be unsurprising to see a word embedding be used to easily evaluate the local grammatical correctness of text.
will resemble grammatically correct text. We will leave it to the reader to figure out how neural networks trained to produce the CBOW word embedding may be used to evaluate the local grammatical correctness of text. It should therefore be unsurprising to see a word embedding be used to easily evaluate the local grammatical correctness of text.
Distance between words: Given a word embedding , one defines the absolute cosine similarity between  as
as  . In our experience, if the matrix embedding potential is the function
. In our experience, if the matrix embedding potential is the function  and the dimension is too large, then words that appear similar to humans typically do not have very high absolute cosine similarity. Fortunately, by using a more suitable matrix embedding potential such as
and the dimension is too large, then words that appear similar to humans typically do not have very high absolute cosine similarity. Fortunately, by using a more suitable matrix embedding potential such as  or
or 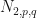 for carefully selected constants
for carefully selected constants  , words that appear similar to humans will have a high absolute cosine similarity. The MPO word embeddings with the matrix embedding potential can still be used to generate locally grammatically correct strings of tokens even though MPO word embeddings with the matrix embedding potential often fail to give words that humans regard as similar a high absolute cosine similarity. We believe that the matrix embedding potential behaves poorly since if is an amplified MPO word embedding with respect to , then there is some matrix
, words that appear similar to humans will have a high absolute cosine similarity. The MPO word embeddings with the matrix embedding potential can still be used to generate locally grammatically correct strings of tokens even though MPO word embeddings with the matrix embedding potential often fail to give words that humans regard as similar a high absolute cosine similarity. We believe that the matrix embedding potential behaves poorly since if is an amplified MPO word embedding with respect to , then there is some matrix 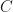 and other amplified MPO word embedding with respect to where
and other amplified MPO word embedding with respect to where  for and where
for and where 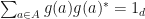 . The requirement for to be similar to a function that uses all dimensions of
. The requirement for to be similar to a function that uses all dimensions of 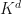 equally is too stringent and needs to be relaxed.
equally is too stringent and needs to be relaxed.
Contextual embeddings: Suppose that is an MPO word embedding. Suppose now that 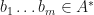 is a string. Let
is a string. Let  be a row vector of length and let
be a row vector of length and let  be a column vector of length . Then let
be a column vector of length . Then let 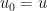 , and let
, and let 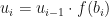 for
for 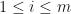 . Then we say that
. Then we say that 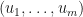 is an MPO left contextual embedding of the string
is an MPO left contextual embedding of the string  with starting vector and we say that
with starting vector and we say that  is an MPO left contextual embedding for position of for
is an MPO left contextual embedding for position of for  . Similarly, let
. Similarly, let 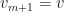 and let
and let  for . Then we say that
for . Then we say that  is an MPO right contextual embedding of the string with respect to the ending vector , and we say that
is an MPO right contextual embedding of the string with respect to the ending vector , and we say that 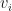 is an MPO right context vector for position whenever
is an MPO right context vector for position whenever  .
.
We can obtain a more sophisticated contextual embedding using the singular value decomposition. Let . Suppose that  has singular value decomposition
has singular value decomposition  . Suppose that the MPO left context vector for the
. Suppose that the MPO left context vector for the  -th position is
-th position is  and the MPO right context vector for the
and the MPO right context vector for the  -th position is
-th position is 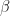 . Then the loss-free context vector for the
. Then the loss-free context vector for the  -th position is
-th position is  . The loss-free context vector for the -th position not only encodes the matrix , but it also encodes the context of
. The loss-free context vector for the -th position not only encodes the matrix , but it also encodes the context of 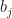 so that the machine can determine the particular meaning of the token .
so that the machine can determine the particular meaning of the token .
The -spectral radius of a collection of matrices  is the maximum value of the form
is the maximum value of the form  . We say that a collection
. We say that a collection  is an -spectral radius dimensionality reduction LSRDR if
is an -spectral radius dimensionality reduction LSRDR if  is locally maximized.
is locally maximized.
Suppose that . For each , let  be the
be the  -matrix where all the entries are zero except for the entries of the form
-matrix where all the entries are zero except for the entries of the form  where
where 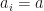 . Then
. Then  Therefore,
Therefore, 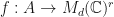 is an amplified MPO word pre-embedding for the sequence with respect to the matrix embedding potential if and only if is an LSRDR for the system of matrices
is an amplified MPO word pre-embedding for the sequence with respect to the matrix embedding potential if and only if is an LSRDR for the system of matrices  . One should therefore consider the notion of the MPO word embedding as an adaptation of the notion of the -spectral radius dimensionality reduction.
. One should therefore consider the notion of the MPO word embedding as an adaptation of the notion of the -spectral radius dimensionality reduction.
Graph embeddings- MPO word embeddings can be used to construct graph embeddings in multiple ways. From any directed or undirected graph, one can obtain a Markov chain simply by taking a random walk on such a graph, and from such a Markov chain, one can obtain sequences and then obtain MPO word embeddings from these sequences.
Let  be finite sets. Suppose that
be finite sets. Suppose that  is a surjective function and let
is a surjective function and let 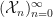 be a Markov chain with underlying set . Then for all
be a Markov chain with underlying set . Then for all  , we have
, we have  , so
, so  induces an MPO word embedding which we shall call an MMPO (Markov matrix product optimized) word embedding induced by the Markov chain and mapping
induces an MPO word embedding which we shall call an MMPO (Markov matrix product optimized) word embedding induced by the Markov chain and mapping  . If
. If 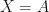 ,
, 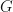 is the identity function, and is the set of vertices of a graph, and the Markov chain is a random walk on this graph, then the MMPO word embeddings induced by and are graph embeddings.
is the identity function, and is the set of vertices of a graph, and the Markov chain is a random walk on this graph, then the MMPO word embeddings induced by and are graph embeddings.
We may also use MPO word embeddings to produce graph embeddings without needing to compute random walks on graphs. Let be a set. Let 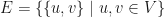 . and let
. and let ![w:E\rightarrow [0,1]](https://s0.wp.com/latex.php?latex=w%3AE%5Crightarrow+%5B0%2C1%5D&bg=ffffff&fg=111111&s=0&c=20201002) be a function with
be a function with  which we shall call a weight function. Now consider the Markov chain where the state space of each
which we shall call a weight function. Now consider the Markov chain where the state space of each  consists of pairs
consists of pairs 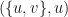 where
where  . If
. If 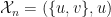 , then set
, then set  with probability
with probability 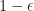 and set
and set  with probability
with probability  whenever
whenever  , and set
, and set 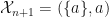 with probability
with probability 
Let  be two functions (
be two functions ( may either be fixed during training or trainable), and let be a matrix embedding potential. If
may either be fixed during training or trainable), and let be a matrix embedding potential. If  is a function, then let
is a function, then let 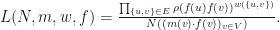 We say that a function is a limit induced MPO pre-embedding if
We say that a function is a limit induced MPO pre-embedding if  is locally maximized. If is a polarizer, then we shall say that is a limit induced MPO pre-embedding. Suppose that is torus invariant, and is a polarizer. Suppose that is a limit induced MPO pre-embedding with respect to the matrix embedding potential . Then let
is locally maximized. If is a polarizer, then we shall say that is a limit induced MPO pre-embedding. Suppose that is torus invariant, and is a polarizer. Suppose that is a limit induced MPO pre-embedding with respect to the matrix embedding potential . Then let  for
for 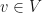 . Define
. Define  by letting
by letting  for . Then we say that is a limit induced MPO embedding with respect to the polarizer if the parameters of the form
for . Then we say that is a limit induced MPO embedding with respect to the polarizer if the parameters of the form  are chosen so that
are chosen so that  is locally maximized.
is locally maximized.
For connected bipartite graphs, we can generalize the notion of a limit induced MPO pre-embedding so that each vertex is associated with a non-square rectangular matrix instead of a square matrix. In this generalization, these non-square rectangular matrices are naturally matrices that cannot be approximated with matrices of lower rank, and since these non-square rectangular matrices are already of maximum rank, one does not need to approximate these matrices with matrices of lower rank.
Suppose that 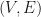 is a bipartite graph with bipartition
is a bipartite graph with bipartition  . Suppose that
. Suppose that  are natural numbers with
are natural numbers with  . Then let
. Then let  be functions. Then we say that
be functions. Then we say that  is a rectangular bipartite limit induced MPO (RBLIMPO) pre-embedding with respect to the function if the following quantity is maximized:
is a rectangular bipartite limit induced MPO (RBLIMPO) pre-embedding with respect to the function if the following quantity is maximized: 
Suppose now that is torus invariant. Then we say that an RBLIMPO pre-embedding is an RBLIMPO embedding if  for
for  is a local maximum for the function
is a local maximum for the function  defined by
defined by 
Crossing near singularities (added 3/5/2023)
When the underlying field is the field of real numbers, MPO word embeddings will behave poorly and gradient ascent will not find a good local optimum with an improper initalization. In order to better illustrate the behavior of real MPO word embeddings, we shall set the fitness function  to be
to be  for some normalizer and string ;
for some normalizer and string ; 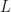 approximates a fitness function that we normally use for MPO word embeddings. Let be the set of all functions where
approximates a fitness function that we normally use for MPO word embeddings. Let be the set of all functions where  . In other words, is the set of all where
. In other words, is the set of all where  or where
or where 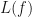 is undefined. If , then
is undefined. If , then  has many components, and each of these components has a local maximum. Furthermore, by using gradient ascent with a small enough learning rate, one will reach a local maximum in the same component as the initialization, but the component of a poor initialization may not contain a decent word embedding. Furthermore, if the initialization is random, then the trained word embedding will be in a random component which is is suboptimal. One can ensure that the initialization is in the proper component by initially setting each entry in each matrix to be positive. In the case when , after fully training an MPO word pre-embedding with an initialization with only positive entries, one does not need to further train the MPO word pre-embedding to obtain an MPO word embedding since the matrices of the form will already have the correct sign and will not need to be multiplied by
has many components, and each of these components has a local maximum. Furthermore, by using gradient ascent with a small enough learning rate, one will reach a local maximum in the same component as the initialization, but the component of a poor initialization may not contain a decent word embedding. Furthermore, if the initialization is random, then the trained word embedding will be in a random component which is is suboptimal. One can ensure that the initialization is in the proper component by initially setting each entry in each matrix to be positive. In the case when , after fully training an MPO word pre-embedding with an initialization with only positive entries, one does not need to further train the MPO word pre-embedding to obtain an MPO word embedding since the matrices of the form will already have the correct sign and will not need to be multiplied by  to obtain an MPO word embedding. Every real MPO word pre-embedding whose initialization consists of matrices with only positive entries shall be called an MPO word embedding.
to obtain an MPO word embedding. Every real MPO word pre-embedding whose initialization consists of matrices with only positive entries shall be called an MPO word embedding.
By setting or , one can avoid this problem of singularities since the set will have real codimension 2 and real codimension 4 in the case when .
Future posts- Future posts on this site will be about other machine learning algorithms that are similar to the MPO word embedding algorithm and the -spectral radius. We will also make a post about computing gradients of the spectral radius and other quantities so that computers can use gradient ascent to compute MPO word embeddings, LSRDRs and other objects. In future posts, we shall analyze the performance of MPO word embeddings and other algorithms.
Open directions-
Much research on MPO word embeddings and related ideas is still needed. Here are a few questions about such research.
How would natural language models use matrix-valued, projective, or complex-valued data produced by MPO word embeddings?
How well do MPO word embeddings perform on large collections of text? The largest collection of text which I have used to train a word embedding was the Bible.
What are some other examples of matrix-valued word embeddings? There are probably other kinds of matrix-valued word embeddings that still need to be discovered. These other embeddings will probably be more interpretable and safe than our current word embeddings. One may even be able to modify our current language models so that they use matrix-valued word embeddings instead of vector-valued word embeddings. I conjecture that language models that use matrix-valued word embeddings are more interpretable and safer than corresponding language models that use vector-valued word embeddings.
Post edited 11/26/2023
References:
[GGW] Gao, Junbin and Guo, Yi and Wang, Zhiyong. Matrix Neural Networks. 2016
