In this post, we shall discuss various generalizations of the notion of the spectral radius to a sort of spectral radius for collections of multiple operators, and we shall develop the theory of the 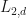 -spectral radius
-spectral radius  . This post consists of the new mathematical research on spectral radii which I will apply to measure the cryptographic security of block cipher round functions with very small key space and small message space. The results that are about the -spectral radii
. This post consists of the new mathematical research on spectral radii which I will apply to measure the cryptographic security of block cipher round functions with very small key space and small message space. The results that are about the -spectral radii  are due to J. Van Name unless otherwise stated while all other results stated are due to others unless otherwise or are standard results in quantum information theory. This post shall be a purely mathematical post, so this post will not contain any cryptography nor will we discuss algorithms that one can use to compute the spectral radii or at least bounds for the spectral radii. I expect for the notion of the -spectral radius to extend to infinite dimensional Hilbert spaces, but no one has formulated such a generalization yet. Future posts about spectral radii will be about the application of spectral radii to cryptography, algorithms, the results of these computations, and possible an -spectral radius for infinite dimensional spaces.
are due to J. Van Name unless otherwise stated while all other results stated are due to others unless otherwise or are standard results in quantum information theory. This post shall be a purely mathematical post, so this post will not contain any cryptography nor will we discuss algorithms that one can use to compute the spectral radii or at least bounds for the spectral radii. I expect for the notion of the -spectral radius to extend to infinite dimensional Hilbert spaces, but no one has formulated such a generalization yet. Future posts about spectral radii will be about the application of spectral radii to cryptography, algorithms, the results of these computations, and possible an -spectral radius for infinite dimensional spaces.
This post includes a large amount of linear algebra and quantum information theory. I recommend the book The Theory of Quantum Information by John Watrous (2018) for information about quantum information theory; most of the facts about linear algebra and quantum information theory that I state but do not prove can be found in The Theory of Quantum Information. I intend for this post to be accessible to people who understand linear algebra but who do not necessarily have much knowledge about functional analysis, quantum information theory, quantum computation, or quantum mechanics.
Spectral radius
Suppose that  is a complex Banach space that contains an operation
is a complex Banach space that contains an operation  that makes into a unital ring. Then we say that is a unital Banach algebra if
that makes into a unital ring. Then we say that is a unital Banach algebra if  whenever
whenever  and if
and if 
If  , then the spectrum
, then the spectrum  of
of  is the set of all complex numbers
is the set of all complex numbers  where
where  is not invertible. If is a square complex matrix, then is simply the set of all eigenvalues of . The spectrum is always a compact non-empty subset of
is not invertible. If is a square complex matrix, then is simply the set of all eigenvalues of . The spectrum is always a compact non-empty subset of  . Define the spectral radius
. Define the spectral radius  of to be
of to be  . The following theorem motivates the spectral radius as a measure of the growth rate of
. The following theorem motivates the spectral radius as a measure of the growth rate of 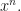
Theorem: If , then 
We have 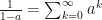 whenever
whenever 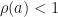 and this sum converges absolutely. On the other hand,
and this sum converges absolutely. On the other hand,  diverges whenever
diverges whenever  . More generally,
. More generally,  is the radius of convergence of the power series
is the radius of convergence of the power series  .
.
We may generalize the notion of the spectral radius to a spectral radius of multiple operators in several different ways. If is a Banach algebra, 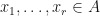 , and
, and 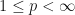 , then define the
, then define the 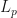 -spectral radius as
-spectral radius as ![\rho_{p}(x_{1},\dots,x_{r})=\lim_{n\rightarrow\infty}[\sum_{(i_{1},\dots,i_{n})\in\{1,\dots,r\}^{n}}\|x_{i_{1}}\dots x_{i_{n}}\|^{p}]^{1/(np)}](https://s0.wp.com/latex.php?latex=%5Crho_%7Bp%7D%28x_%7B1%7D%2C%5Cdots%2Cx_%7Br%7D%29%3D%5Clim_%7Bn%5Crightarrow%5Cinfty%7D%5B%5Csum_%7B%28i_%7B1%7D%2C%5Cdots%2Ci_%7Bn%7D%29%5Cin%5C%7B1%2C%5Cdots%2Cr%5C%7D%5E%7Bn%7D%7D%5C%7Cx_%7Bi_%7B1%7D%7D%5Cdots+x_%7Bi_%7Bn%7D%7D%5C%7C%5E%7Bp%7D%5D%5E%7B1%2F%28np%29%7D&bg=ffffff&fg=111111&s=0&c=20201002) (it is not too hard to show that this limit exists). Observe that when
(it is not too hard to show that this limit exists). Observe that when  , this definition of
, this definition of  does not depend on the choice of norm, and this definition still holds even if we drop the requirement that the norm is sub-multiplicative. Define
does not depend on the choice of norm, and this definition still holds even if we drop the requirement that the norm is sub-multiplicative. Define ![\rho_{\infty}(x_1,\dots,x_r)=\lim_{n\rightarrow\infty}[\sup_{(i_{1},\dots,i_{n})\in\{1,\dots,r\}^{n}}\|x_{i_{1}}\dots x_{i_{n}}\|]^{1/n}](https://s0.wp.com/latex.php?latex=%5Crho_%7B%5Cinfty%7D%28x_1%2C%5Cdots%2Cx_r%29%3D%5Clim_%7Bn%5Crightarrow%5Cinfty%7D%5B%5Csup_%7B%28i_%7B1%7D%2C%5Cdots%2Ci_%7Bn%7D%29%5Cin%5C%7B1%2C%5Cdots%2Cr%5C%7D%5E%7Bn%7D%7D%5C%7Cx_%7Bi_%7B1%7D%7D%5Cdots+x_%7Bi_%7Bn%7D%7D%5C%7C%5D%5E%7B1%2Fn%7D&bg=ffffff&fg=111111&s=0&c=20201002) (this limit exists) . We can also write
(this limit exists) . We can also write 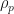 in terms of the
in terms of the  norm for
norm for  by letting
by letting 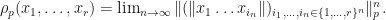 Here,
Here,  denotes the norm.
denotes the norm.
If 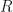 is a ring and
is a ring and 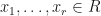 , then we say that
, then we say that  is jointly nilpotent if
is jointly nilpotent if  for all but finitely many strings
for all but finitely many strings  .
.
Basic observations: Suppose that is a Banach algebra and  . Let
. Let 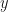 be an invertible element in . Suppose that
be an invertible element in . Suppose that  Let
Let 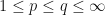 .
.
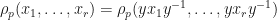 whenever is an invertible element in .
whenever is an invertible element in .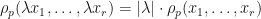 for each scalar .
for each scalar . whenever
whenever 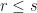 .
. .
.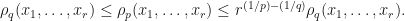

 if and only if
if and only if  is jointly nilpotent.
is jointly nilpotent. 
To prove the above fact, we use the fact that if 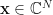 , then
, then 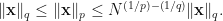
While the spectral radii  are distinct important generalizations of the notion of a spectral radius, for this post, we shall be primarily concerned with the spectral radius
are distinct important generalizations of the notion of a spectral radius, for this post, we shall be primarily concerned with the spectral radius  . For the rest of this post, we shall assume all vector spaces are finite dimensional inner product spaces.
. For the rest of this post, we shall assume all vector spaces are finite dimensional inner product spaces.
Let 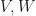 be a finite dimensional complex inner product spaces. Let
be a finite dimensional complex inner product spaces. Let  denote the space of all linear operators from
denote the space of all linear operators from  to
to 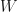 , and let
, and let  . If
. If  , then define a mapping
, then define a mapping  by letting
by letting 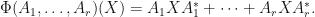 Throughout this post, we shall implicitly use the fact that the operator
Throughout this post, we shall implicitly use the fact that the operator  is similar to
is similar to 
If , then recall that the  -Schatten norm of a complex matrix is defined by letting
-Schatten norm of a complex matrix is defined by letting 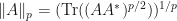 for and
for and 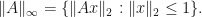 If
If  are the singular values of , then
are the singular values of , then  . If
. If  are real or complex matrices with the same dimensions, then define the Frobenius inner product
are real or complex matrices with the same dimensions, then define the Frobenius inner product 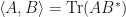 . Observe that
. Observe that 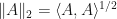 . If
. If 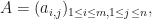 then
then 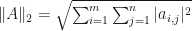 .
.
The following proposition was originally proven by Ding-Xuan Zhou in the 1998 paper titled The -norm joint spectral radius for even integers.
Proposition:  .
.
Proof: Let 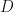 be the collection of all positive semidefinite matrices
be the collection of all positive semidefinite matrices 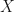 with
with 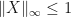 . Observe that if is positive semidefinite, then
. Observe that if is positive semidefinite, then  if and only if
if and only if 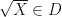 . We will need to use the fact that
. We will need to use the fact that  .
.
For this proof, the norm 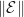 on an operator
on an operator  from
from  to shall be the maximum value of
to shall be the maximum value of 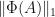 such that
such that  . We have
. We have


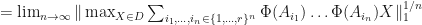
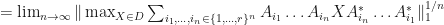
![=\lim_{n\rightarrow\infty}[\max_{X\in D}\sum_{i_{1},\dots,i_{n}\in\{1,\dots,r\}^{n}}\text{Tr}(\sqrt{X}A_{i_{n}}^{*}\dots A_{i_{1}}^{*}A_{i_{1}}\dots A_{i_{n}}\sqrt{X})]^{1/n}](https://s0.wp.com/latex.php?latex=%3D%5Clim_%7Bn%5Crightarrow%5Cinfty%7D%5B%5Cmax_%7BX%5Cin+D%7D%5Csum_%7Bi_%7B1%7D%2C%5Cdots%2Ci_%7Bn%7D%5Cin%5C%7B1%2C%5Cdots%2Cr%5C%7D%5E%7Bn%7D%7D%5Ctext%7BTr%7D%28%5Csqrt%7BX%7DA_%7Bi_%7Bn%7D%7D%5E%7B%2A%7D%5Cdots+A_%7Bi_%7B1%7D%7D%5E%7B%2A%7DA_%7Bi_%7B1%7D%7D%5Cdots+A_%7Bi_%7Bn%7D%7D%5Csqrt%7BX%7D%29%5D%5E%7B1%2Fn%7D&bg=ffffff&fg=111111&s=0&c=20201002)
![=\lim_{n\rightarrow\infty}[\max_{X\in D}\sum_{i_{1},\dots,i_{n}\in\{1,\dots,r\}^{n}}\|A_{i_{1}}\dots A_{i_{n}}\sqrt{X}\|^{2}_{2}]^{1/n}](https://s0.wp.com/latex.php?latex=%3D%5Clim_%7Bn%5Crightarrow%5Cinfty%7D%5B%5Cmax_%7BX%5Cin+D%7D%5Csum_%7Bi_%7B1%7D%2C%5Cdots%2Ci_%7Bn%7D%5Cin%5C%7B1%2C%5Cdots%2Cr%5C%7D%5E%7Bn%7D%7D%5C%7CA_%7Bi_%7B1%7D%7D%5Cdots+A_%7Bi_%7Bn%7D%7D%5Csqrt%7BX%7D%5C%7C%5E%7B2%7D_%7B2%7D%5D%5E%7B1%2Fn%7D&bg=ffffff&fg=111111&s=0&c=20201002)
=![=\lim_{n\rightarrow\infty}[\sum_{i_{1},\dots,i_{n}\in\{1,\dots,r\}^{n}}\|A_{i_{1}}\dots A_{i_{n}}\|^{2}_{2}]^{1/n}=\rho_{2}(A_{1},\dots,A_{r})^{2}](https://s0.wp.com/latex.php?latex=%3D%5Clim_%7Bn%5Crightarrow%5Cinfty%7D%5B%5Csum_%7Bi_%7B1%7D%2C%5Cdots%2Ci_%7Bn%7D%5Cin%5C%7B1%2C%5Cdots%2Cr%5C%7D%5E%7Bn%7D%7D%5C%7CA_%7Bi_%7B1%7D%7D%5Cdots+A_%7Bi_%7Bn%7D%7D%5C%7C%5E%7B2%7D_%7B2%7D%5D%5E%7B1%2Fn%7D%3D%5Crho_%7B2%7D%28A_%7B1%7D%2C%5Cdots%2CA_%7Br%7D%29%5E%7B2%7D&bg=ffffff&fg=111111&s=0&c=20201002) . Q.E.D.
. Q.E.D.
Corollary: If is an even integer, then  .
.
Proposition: Suppose that  are positive real numbers with
are positive real numbers with  . Then
. Then  .
.
Proof: Assume that our matrix norm satisfies the property  for all matrices . By applying Holder’s inequality, we perform the following calculations.
for all matrices . By applying Holder’s inequality, we perform the following calculations.




![\leq\lim_{n\rightarrow\infty}[\sum_{i_{1},\dots,i_{n}\in\{1,\dots,r\}}\|(A_{i_{1}}\dots A_{i_{n}})\otimes(B_{i_{1}}\dots B_{i_{n}})\|]^{1/n}](https://s0.wp.com/latex.php?latex=%5Cleq%5Clim_%7Bn%5Crightarrow%5Cinfty%7D%5B%5Csum_%7Bi_%7B1%7D%2C%5Cdots%2Ci_%7Bn%7D%5Cin%5C%7B1%2C%5Cdots%2Cr%5C%7D%7D%5C%7C%28A_%7Bi_%7B1%7D%7D%5Cdots+A_%7Bi_%7Bn%7D%7D%29%5Cotimes%28B_%7Bi_%7B1%7D%7D%5Cdots+B_%7Bi_%7Bn%7D%7D%29%5C%7C%5D%5E%7B1%2Fn%7D&bg=ffffff&fg=111111&s=0&c=20201002)
![=\lim_{n\rightarrow\infty}[\sum_{i_{1},\dots,i_{n}\in\{1,\dots,r\}}\|A_{i_{1}}\dots A_{i_{n}}\|\cdot\|B_{i_{1}}\dots B_{i_{n}}\|]^{1/n}](https://s0.wp.com/latex.php?latex=%3D%5Clim_%7Bn%5Crightarrow%5Cinfty%7D%5B%5Csum_%7Bi_%7B1%7D%2C%5Cdots%2Ci_%7Bn%7D%5Cin%5C%7B1%2C%5Cdots%2Cr%5C%7D%7D%5C%7CA_%7Bi_%7B1%7D%7D%5Cdots+A_%7Bi_%7Bn%7D%7D%5C%7C%5Ccdot%5C%7CB_%7Bi_%7B1%7D%7D%5Cdots+B_%7Bi_%7Bn%7D%7D%5C%7C%5D%5E%7B1%2Fn%7D&bg=ffffff&fg=111111&s=0&c=20201002)
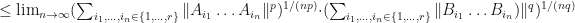

Q.E.D.
The above inequality is sharp when 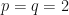 since
since  .
.
Example: If  are unitary matrices, then
are unitary matrices, then  More generally, if
More generally, if  are constants, then
are constants, then 
Example: Suppose that  are matrices. Then
are matrices. Then 
Example: If  are matrices, then
are matrices, then 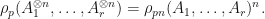
Quantum information theory
A mapping 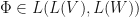 is said to be positive if
is said to be positive if  is positive semidefinite whenever
is positive semidefinite whenever 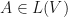 is positive semidefinite. The mapping
is positive semidefinite. The mapping  is said to be completely positive if
is said to be completely positive if 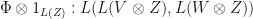 is positive whenever
is positive whenever 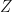 is a finite dimensional complex inner product space. The mapping is said to be trace preserving if
is a finite dimensional complex inner product space. The mapping is said to be trace preserving if  for each
for each  The mapping is said to be unital if
The mapping is said to be unital if 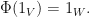 A mapping is said to be a quantum channel if is completely positive and trace preserving.
A mapping is said to be a quantum channel if is completely positive and trace preserving.
If 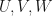 are complex vector spaces, then there is a unique linear mapping
are complex vector spaces, then there is a unique linear mapping 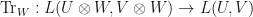 where
where  whenever
whenever  . This linear mapping is known as the partial trace.
. This linear mapping is known as the partial trace.
Observation: Suppose that 
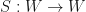 , and
, and  . Then
. Then

 and
and
If  are finite dimensional complex inner product spaces, then
are finite dimensional complex inner product spaces, then  are inner product spaces with the Frobenius norm. In this case, if
are inner product spaces with the Frobenius norm. In this case, if 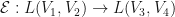 is a linear mapping, then the adjoint
is a linear mapping, then the adjoint 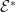 of is the adjoint with respect to the Frobenius norms on
of is the adjoint with respect to the Frobenius norms on  and
and  .
.
Let 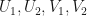 be finite dimensional complex inner product spaces. Every mapping in
be finite dimensional complex inner product spaces. Every mapping in  is a linear combinational of mappings of the form
is a linear combinational of mappings of the form  where
where  Therefore, if
Therefore, if  , then let
, then let  be the mapping defined by letting
be the mapping defined by letting 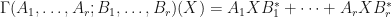 whenever
whenever 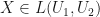 . If
. If  , then let
, then let  be the mapping defined by letting
be the mapping defined by letting 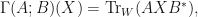 and define by letting
and define by letting  We shall sometimes write
We shall sometimes write  for
for  and
and  for in order to specify the vector space . Observe that
for in order to specify the vector space . Observe that  and
and  , and
, and  whenever these equations make sense.
whenever these equations make sense.
The linear operator  is similar to the linear operator
is similar to the linear operator 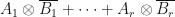 .
.
Theorem: Let 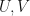 be finite dimensional complex inner product spaces. Let
be finite dimensional complex inner product spaces. Let  be a linear mapping. The following are equivalent:
be a linear mapping. The following are equivalent:
Theorem: Let be finite dimensional complex inner product spaces. Let be a linear mapping. The following are equivalent:
- is completely positive.
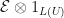 is positive.
is positive. for some
for some  and
and  .
. for some finite dimensional complex inner product space and
for some finite dimensional complex inner product space and  .
.
Theorem: Let be finite dimensional complex inner product spaces. Let be a linear mapping. Then the operator is trace preserving if and only if its adjoint is unital.
Theorem
1: Let  . Then
. Then
i. The following are equivalent:
a. is trace preserving.
b. 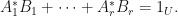
c.  .
.
ii. The following are equivalent:
a. is unital.
b.  .
.
c.  .
.
2. Let  Then
Then
i. The following are equivalent:
a. is trace preserving.
b.  .
.
c.  .
.
ii. The following are equivalent:
a. is unital.
b. 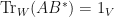 .
.
c. 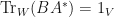 .
.
Theorem: Suppose that 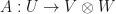 and
and  are linear. The mapping is a quantum channel if and only if is an isometry. The mapping is a quantum channel if and only if
are linear. The mapping is a quantum channel if and only if is an isometry. The mapping is a quantum channel if and only if 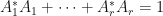 .
.
Example: The completely depolarizing channel is the channel  defined by letting
defined by letting  . The completely depolarizing channel is unital. If
. The completely depolarizing channel is unital. If 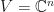 , then let
, then let  be the
be the  -matrix defined by letting
-matrix defined by letting  where
where  refers to the Kronecker delta function. Then
refers to the Kronecker delta function. Then  . We shall write
. We shall write  in order to specify the space , and we shall write
in order to specify the space , and we shall write 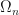 for
for  .
.
Example: Suppose that  is a probability vector. Let be a finite dimensional complex inner product space. Let
is a probability vector. Let be a finite dimensional complex inner product space. Let  be unitary operators. Then let
be unitary operators. Then let  be the function where
be the function where  for each
for each  . Then we say that
. Then we say that  is mixed unitary. Every mixed unitary operator is a unital channel, but not every unitary channel is mixed unitary. However, John Watrous has shown that there is a neighborhood
is mixed unitary. Every mixed unitary operator is a unital channel, but not every unitary channel is mixed unitary. However, John Watrous has shown that there is a neighborhood 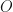 of the completely depolarizing channel where if
of the completely depolarizing channel where if  , then is mixed unitary if and only if it is unital.
, then is mixed unitary if and only if it is unital.
Example: The complete dephasing channel is the channel  defined by letting
defined by letting  precisely when
precisely when 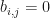 for
for 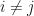 and
and  for
for  . Suppose that
. Suppose that  are the matrices where
are the matrices where  for and where the addition in the subscript is taken modulo
for and where the addition in the subscript is taken modulo  . Then
. Then 
Example: The shifted complete dephasing channel is the channel  defined by letting precisely when for and
defined by letting precisely when for and  for where the addition in the subscripts is taken modulo . Suppose now that
for where the addition in the subscripts is taken modulo . Suppose now that  are the matrices where
are the matrices where  for and where the addition in the subscript is taken modulo . Then
for and where the addition in the subscript is taken modulo . Then 
Example: The shifted complete dephasing channel is the channel defined by letting precisely when for and for where the addition in the subscripts is taken modulo . Suppose now that are the matrices where for and where the addition in the subscript is taken modulo . Then
Proposition: If  is positive and either trace preserving or unital, then
is positive and either trace preserving or unital, then  .
.
Proof outline: Since is trace preserving if and only if its adjoint is unital, we only have to prove this result when is trace preserving.
If  is positive and trace preserving, then whenever is positive semidefinite, we have
is positive and trace preserving, then whenever is positive semidefinite, we have 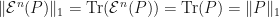 . From this fact, one can easily conclude that . Q.E.D.
. From this fact, one can easily conclude that . Q.E.D.
Proposition: If  is positive and
is positive and  whenever is a positive semidefinite matrix with
whenever is a positive semidefinite matrix with  , then has a positive semidefinite eigenvector with non-zero eigenvector.
, then has a positive semidefinite eigenvector with non-zero eigenvector.
Proof: Let 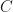 be the collection of all positive semidefinite operators
be the collection of all positive semidefinite operators  with
with 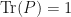 . Define a mapping
. Define a mapping  by letting
by letting  Then by Brouwer’s fixed point theorem, there is some
Then by Brouwer’s fixed point theorem, there is some 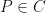 with
with  . Therefore,
. Therefore,  .
.
Q.E.D.
Corollary: If is positive and trace preserving, then there is a positive semidefinite with and 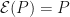 .
.
Proposition: If is a positive mapping. If is a positive definite eigenvector, then 
Proof: Suppose that is an eigenvalue with  and is an eigenvector with
and is an eigenvector with  . Then there are positive semidefinite
. Then there are positive semidefinite 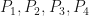 with
with  . Therefore, there is some
. Therefore, there is some  with
with  for all
for all  .
.
For all , we have 
 This is only possible if
This is only possible if 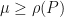 .
.
Q.E.D.
Tensor products
We will apply the following observations about tensor products and related constructions to the -spectral radius.
Proposition: Suppose that 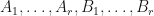 are
are 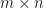 -complex matrices. Then
-complex matrices. Then 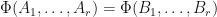 if and only if there is an
if and only if there is an 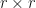 -unitary matrix
-unitary matrix  such that
such that 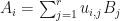 for
for  .
.
Lemma: Suppose that  are linear operators. Then
are linear operators. Then 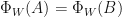 if and only if there is a unitary
if and only if there is a unitary  such that
such that 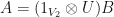 .
.
Lemma: Suppose that  are matrices over a field
are matrices over a field 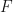 where are of the same dimensions and
where are of the same dimensions and  are of the same dimensions. Let
are of the same dimensions. Let 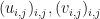 be -matrices over the field . Suppose furthermore that
be -matrices over the field . Suppose furthermore that 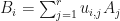 and
and  for . If
for . If  , then
, then 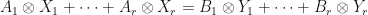 .
.
Lemma: Suppose that are complex matrices where have the same dimensions, and have the same dimensions. Let be complex -matrices. Suppose that and 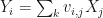 for and
for and  , then
, then 
Lemma: Let  be finite dimensional complex inner product spaces. Suppose that and
be finite dimensional complex inner product spaces. Suppose that and  are linear mappings. Let
are linear mappings. Let 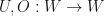 be linear mappings. Suppose that
be linear mappings. Suppose that 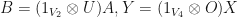 and
and  . Then
. Then 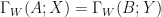 .
.
Proposition: Let be finite dimensional complex inner product spaces. Let  be linear. Let
be linear. Let  be an orthonormal basis for . Let
be an orthonormal basis for . Let  be linear. Suppose that
be linear. Suppose that  . Then
. Then  .
.
Observation: Let be finite dimensional complex inner product spaces. Suppose that is an orthonormal basis for . Let  be linear operators. Suppose that are linear operators and
be linear operators. Suppose that are linear operators and  . Let
. Let  be linear. Then
be linear. Then 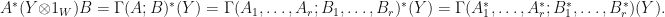
Proposition: Let  be finite dimensional complex inner product spaces. Suppose that
be finite dimensional complex inner product spaces. Suppose that  are linear mappings. Let be an orthonormal basis for . Let
are linear mappings. Let be an orthonormal basis for . Let 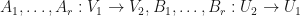 be linear maps. Suppose that
be linear maps. Suppose that 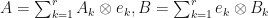 . Then
. Then 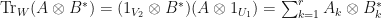 .
.
-spectral radius.
Let  be the collection of all tuples
be the collection of all tuples 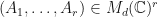 which are not jointly nilpotent. Suppose that are complex matrices. Then define the -spectral radius of
which are not jointly nilpotent. Suppose that are complex matrices. Then define the -spectral radius of  by
by 
By the Cauchy-Schwarz inequality  , we know that
, we know that 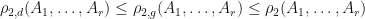 whenever
whenever  , and since
, and since 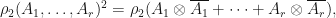 we know that if
we know that if 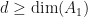 , then
, then 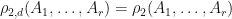 .
.
Proposition: Suppose that  are complex matrices. Suppose that there is a unitary matrix
are complex matrices. Suppose that there is a unitary matrix  such that
such that  for . Then
for . Then  .
.
Proof: Let  Then
Then 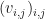 is unitary. Suppose now that
is unitary. Suppose now that  . Then there are
. Then there are 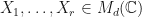 with
with  Now set
Now set  for , then
for , then  and
and  . Therefore,
. Therefore,  , so
, so  . We can therefore conclude that
. We can therefore conclude that 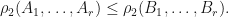
For the reverse inequality, observe that if  , then
, then  and
and  is unitary, so we can conclude that
is unitary, so we can conclude that  as well.
as well.
Q.E.D.
Corollary: If , then 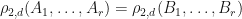 for all
for all 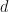 .
.
If is a completely positive superoperator, then define  by letting
by letting  whenever . By the above corollary, the quantity is well-defined. If
whenever . By the above corollary, the quantity is well-defined. If  is a linear operator, then define
is a linear operator, then define 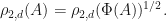
Observation: Let be finite dimensional complex inner product spaces with  . Let
. Let 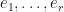 be an orthonormal basis for . Let
be an orthonormal basis for . Let  and let . Let
and let . Let  , and let
, and let 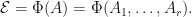 Then the following quantities are equivalent:
Then the following quantities are equivalent:

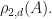


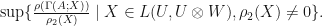

 .
.
Proof outline: By definition 1-3 are equivalent to each other. The equivalence between 1 and 4 follows from the fact that 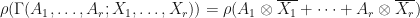 and
and  The equivalence between 4 and 5 follows from the fact that if
The equivalence between 4 and 5 follows from the fact that if  and
and 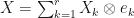 , then
, then  and
and  The equivalence between 6 and 7 follows from the fact that
The equivalence between 6 and 7 follows from the fact that  . The equivalence between 1 and 7 follows from the fact that
. The equivalence between 1 and 7 follows from the fact that  and
and 
Q.E.D.
We shall soon see how in the above result, each of the suprema can actually be reached, so we can replace each supremum with a maximum.
Proposition: Suppose that are -complex matrices. Suppose furthermore that there is an invertible -complex matrix , a complex number and a unitary matrix such that  for . Then
for . Then  .
.
Proof: It is easy to see that  . Furthermore, since
. Furthermore, since  , we know that
, we know that 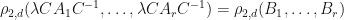 as well. Q.E.D.
as well. Q.E.D.
Lemma: Suppose that  are linear operators. If
are linear operators. If  , then
, then 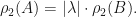
Proof: We have 
 . Therefore,
. Therefore,  is similar to
is similar to 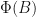 , so
, so 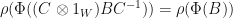 . We therefore conclude that
. We therefore conclude that  . Furthermore, we have
. Furthermore, we have 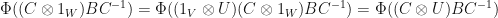 , so
, so 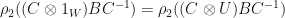 as well.
as well.
Q.E.D.
Lemma: Suppose that are linear operators. If 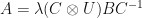 , then
, then 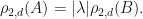
Proof: Observe that 
 . Therefore,
. Therefore, 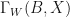 is similar to
is similar to 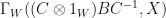 , so
, so 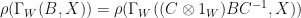 . We conclude that
. We conclude that  , and clearly
, and clearly 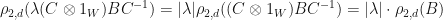 .
.
Now, since , we know that
 . Q.E.D.
. Q.E.D.
Quantum channels and spectral radii
Here, we give theorems that interpret the spectral radii in terms of quantum channels.
Let be finite dimensional complex Hilbert spaces. Suppose that is a positive mapping. Suppose that has a positive definite eigenvector with non-zero (necessarily positive) eigenvalue . Then define a positive operator 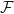 by
by  . Then is unital.
. Then is unital.
Suppose that is a positive mapping. Suppose that has a positive definite eigenvector with non-zero (necessarily positive) eigenvalue . Then define a mapping by letting  . Then is trace preserving and positive. In particular, if is a completely positive, and has a positive definite eigenvector , then is a quantum channel.
. Then is trace preserving and positive. In particular, if is a completely positive, and has a positive definite eigenvector , then is a quantum channel.
We say that a positive operator is pre-unital if has a positive definite eigenvector with non-zero (necessarily positive) eigenvalue . We say that a positive operator is pre-trace preserving if has a positive definite eigenvector with non-zero (necessarily positive) eigenvalue .
We say that a tuple  is pre-unital (pre-trace preserving) if is pre-unital (pre-trace preserving). We say that
is pre-unital (pre-trace preserving) if is pre-unital (pre-trace preserving). We say that  is pre-unital (pre-trace preserving) if is pre-unital (pre-trace preserving).
is pre-unital (pre-trace preserving) if is pre-unital (pre-trace preserving).
Proposition: Let be a finite dimensional complex inner product space. Let be a positive operator. The following are equivalent:
- is pre-unital.
- There is some positive definite and non-zero where if
 , then is unital.
, then is unital. - There is some invertible and non-zero where if
 , then is unital.
, then is unital.
In particular,  is the spectral radius of the operator
is the spectral radius of the operator
Proposition: Let be a finite dimensional complex inner product space. Let be a positive operator. The following are equivalent:
- is pre-trace preserving.
- There is some positive definite and non-zero where if , then is trace preserving.
- There is some invertible and non-zero where if , then is trace preserving.
Proposition: Let be finite dimensional complex inner product spaces where is an orthonormal basis for . Let  and suppose that . Then the following are equivalent:
and suppose that . Then the following are equivalent:
- is pre unital.
- There exists some invertible
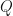 and some
and some  where
where  is unital.
is unital. - There is some positive definite and some where is unital.
- There exists some invertible and some where
 is unital.
is unital. - There exists some positive definite and some where is unital.
Proposition: Let be finite dimensional complex inner product spaces where has orthonormal basis . Let , and suppose that . Then the following are equivalent:
- is pre-trace preserving.
- There exists some invertible and some where
 is trace preserving.
is trace preserving. - There is some positive definite and some where is trace preserving.
- There exists some invertible and some where is trace-preserving.
- There exists some positive definite and some where is trace-preserving.
Observation: Let be finite dimensional complex vector spaces and let  be a subspace of
be a subspace of 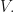 Let
Let 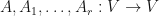 be linear operators. Let
be linear operators. Let 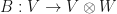 be a linear operator. Let
be a linear operator. Let  be positive semidefinite.
be positive semidefinite.
 .
.![A^*[U]^\perp=A^{-1}[U^\perp]](https://s0.wp.com/latex.php?latex=A%5E%2A%5BU%5D%5E%5Cperp%3DA%5E%7B-1%7D%5BU%5E%5Cperp%5D&bg=ffffff&fg=111111&s=0&c=20201002)
 .
. .
. .
. .
.![\ker(A^*PA)=A^{-1}[\ker(P)]](https://s0.wp.com/latex.php?latex=%5Cker%28A%5E%2APA%29%3DA%5E%7B-1%7D%5B%5Cker%28P%29%5D&bg=ffffff&fg=111111&s=0&c=20201002) .
. .
.![\text{ran}(APA^*)=A[\text{ran}(P)]](https://s0.wp.com/latex.php?latex=%5Ctext%7Bran%7D%28APA%5E%2A%29%3DA%5B%5Ctext%7Bran%7D%28P%29%5D&bg=ffffff&fg=111111&s=0&c=20201002) .
.![\text{ran}(\Phi(A_1,\dots,A_r)(P))=A_1[\text{ran}(P)]+\dots+A_r[\text{ran}(P)]](https://s0.wp.com/latex.php?latex=%5Ctext%7Bran%7D%28%5CPhi%28A_1%2C%5Cdots%2CA_r%29%28P%29%29%3DA_1%5B%5Ctext%7Bran%7D%28P%29%5D%2B%5Cdots%2BA_r%5B%5Ctext%7Bran%7D%28P%29%5D&bg=ffffff&fg=111111&s=0&c=20201002) .
.![\ker(\Phi(A^*_1,\dots,A^*_r)(P))=A_1^{-1}[\ker(P)]\cap\dots\cap A_r^{-1}[\ker(P)]](https://s0.wp.com/latex.php?latex=%5Cker%28%5CPhi%28A%5E%2A_1%2C%5Cdots%2CA%5E%2A_r%29%28P%29%29%3DA_1%5E%7B-1%7D%5B%5Cker%28P%29%5D%5Ccap%5Cdots%5Ccap+A_r%5E%7B-1%7D%5B%5Cker%28P%29%5D&bg=ffffff&fg=111111&s=0&c=20201002) .
.![\text{ran}(\Phi(B)(P))=\sum_{w\in W}((1_V\otimes w^*)B)[\text{ran}(P)]](https://s0.wp.com/latex.php?latex=%5Ctext%7Bran%7D%28%5CPhi%28B%29%28P%29%29%3D%5Csum_%7Bw%5Cin+W%7D%28%281_V%5Cotimes+w%5E%2A%29B%29%5B%5Ctext%7Bran%7D%28P%29%5D&bg=ffffff&fg=111111&s=0&c=20201002) .
.![\ker(\phi(B)^*(P))=\bigcap_{w\in W}((1_V\otimes w^*)B)^{-1}[\ker(P)]](https://s0.wp.com/latex.php?latex=%5Cker%28%5Cphi%28B%29%5E%2A%28P%29%29%3D%5Cbigcap_%7Bw%5Cin+W%7D%28%281_V%5Cotimes+w%5E%2A%29B%29%5E%7B-1%7D%5B%5Cker%28P%29%5D&bg=ffffff&fg=111111&s=0&c=20201002) .
.
From the following proposition, we can conclude that if 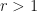 , then almost all tuples are both pre-unital and pre-trace preserving.
, then almost all tuples are both pre-unital and pre-trace preserving.
Proposition: Let be a finite dimensional complex inner product space. Let . Suppose that has no irreducible subspace other than  and . Then is both pre-unital and pre-trace preserving.
and . Then is both pre-unital and pre-trace preserving.
Theorem: (J. Van Name) Let be finite dimensional complex vector spaces where has orthonormal basis and  Let
Let  , and suppose that . Suppose that The following quantities are equivalent:
, and suppose that . Suppose that The following quantities are equivalent:
- .
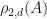 .
. .
.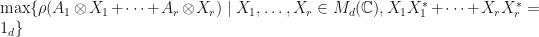 .
. .
.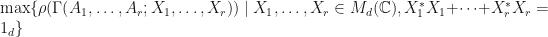 .
.


Proof: Observe that  is compact, so the maximum
is compact, so the maximum 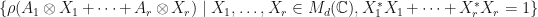 actually exists. By similar arguments, one can show that the maximum exists in 3-9. Furthermore, observe that the quantities in 3-9 are all less than or equal to
actually exists. By similar arguments, one can show that the maximum exists in 3-9. Furthermore, observe that the quantities in 3-9 are all less than or equal to
 Suppose that
Suppose that 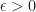 . Then there is some
. Then there is some  where
where  . Therefore, there is a pre-trace preserving and pre-unital
. Therefore, there is a pre-trace preserving and pre-unital 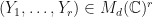 with
with 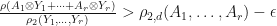 . Since
. Since  is pre-trace preserving, there is some and invertible
is pre-trace preserving, there is some and invertible 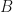 where
where 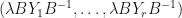 is trace preserving. In this case, if
is trace preserving. In this case, if 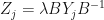 for
for 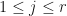 , then
, then 
Therefore, since 
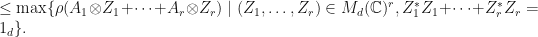
Therefore,
 .
.
Since is pre-unital, there is some 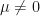 and invertible where
and invertible where  is unital. Let
is unital. Let 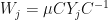 for . In this case, we have
for . In this case, we have  so
so

Thus 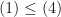 as well.
as well.
The proofs that  are all greater than or equal to are similar to the proofs that
are all greater than or equal to are similar to the proofs that  .
.
Q.E.D.
Let be finite dimensional complex Hilbert spaces. Suppose that is a linear operator. Then define the induced trace norm of as 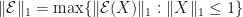 , and define the completely bounded trace norm of as
, and define the completely bounded trace norm of as  . Both the induced trace norm and the completely bounded trace norm are submultiplicative, so
. Both the induced trace norm and the completely bounded trace norm are submultiplicative, so  whenever
whenever  .
.
The proof of following lemma can be found in the 2012 paper ‘Relations for certain symmetric norms and anti-norms before and after partial trace’ by Alexey E. Rastegin.
Lemma: Let be finite dimensional complex inner product spaces. Let  be a linear operator. Suppose that . Then
be a linear operator. Suppose that . Then  . In particular,
. In particular, 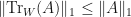 .
.
If 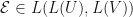 is a positive and trace preserving map, then
is a positive and trace preserving map, then  . If is a quantum channel, then
. If is a quantum channel, then 
Observe that if  . Therefore,
. Therefore,  .
.
Observation: (J. Van Name) Let be finite dimensional complex Hilbert spaces with and where has orthonormal basis . Let and suppose that  is the mapping where
is the mapping where  . Then the following quantities are equivalent:
. Then the following quantities are equivalent:

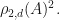





There are other similar formulae for , but for the sake of brevity, we shall leave the task of finding other formulae for to the reader.
Observation:  whenever
whenever  are complex matrices, are isometries, and this product makes sense.
are complex matrices, are isometries, and this product makes sense.
Lemma: Suppose that 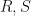 are isometries. Then
are isometries. Then 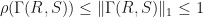 .
.
Proof: Observe that  whenever is an operator. Therefore,
whenever is an operator. Therefore,  . Q.E.D.
. Q.E.D.
Lemma: Suppose that are isometries. Then  .
.
Proof: Suppose that is an eigenvalue for 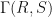 . Then
. Then  for some . Therefore,
for some . Therefore,  . Now, by the polar decomposition, there is a positive semidefinite and an isometry
. Now, by the polar decomposition, there is a positive semidefinite and an isometry 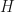 where
where  . Let
. Let  . Now,
. Now, 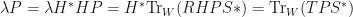 .
.
Suppose that  . Then
. Then  and
and  . Therefore,
. Therefore,  . This is only possible if
. This is only possible if  .
.
Q.E.D.
Theorem: (J. Van Name) Suppose that are finite dimensional complex vector spaces and  . Suppose that is pre-trace preserving, and
. Suppose that is pre-trace preserving, and 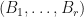 is has no non-trivial invariant subspace. If
is has no non-trivial invariant subspace. If  , then has an invariant subspace
, then has an invariant subspace  and there is a linear bijection
and there is a linear bijection  and non-zero
and non-zero 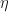 with
with 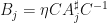 for where
for where  is the restriction of
is the restriction of  to the invariant subspace .
to the invariant subspace .
Proof: Since are both pre-trace preserving, there are matrices and non-zero complex numbers  such that if
such that if  for , then
for , then  are quantum channels. Suppose now that
are quantum channels. Suppose now that  . Then
. Then
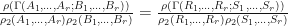

Suppose now that  are the same as in the above lemma, and suppose that
are the same as in the above lemma, and suppose that  . Then
. Then  .
.
This is only possible if 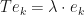 whenever
whenever  . This happens precisely when
. This happens precisely when  . Therefore, we have
. Therefore, we have 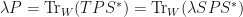 . We therefore, conclude that
. We therefore, conclude that  . The positive definite matrix is positive definite, so
. The positive definite matrix is positive definite, so 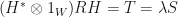 .
.
Suppose that  . Then
. Then  . Therefore,
. Therefore,  whenever .
whenever .
Now, let 
![A_j^\sharp:A^{-1}[\text{Im}(H)]\rightarrow A^{-1}[\text{Im}(H)],A^\sharp:A^{-1}[\text{Im}(H)]\rightarrow\text{Im}(H)](https://s0.wp.com/latex.php?latex=A_j%5E%5Csharp%3AA%5E%7B-1%7D%5B%5Ctext%7BIm%7D%28H%29%5D%5Crightarrow+A%5E%7B-1%7D%5B%5Ctext%7BIm%7D%28H%29%5D%2CA%5E%5Csharp%3AA%5E%7B-1%7D%5B%5Ctext%7BIm%7D%28H%29%5D%5Crightarrow%5Ctext%7BIm%7D%28H%29&bg=ffffff&fg=111111&s=0&c=20201002) be the restrictions of
be the restrictions of  .
.
The mapping 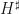 is unitary. Here,
is unitary. Here,  . Therefore,
. Therefore, 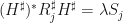 , so
, so 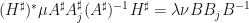 . Therefore,
. Therefore,  , so
, so 
Q.E.D.
Theorem: (J. Van Name) Let be finite dimensional complex inner product spaces. Suppose that are linear operators. Then we can assign the vector spaces bases such that for , we can write the operators  as block matrices to get
as block matrices to get
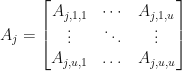 and
and 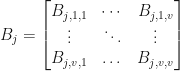
where
i.  whenever
whenever 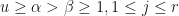 ,
,
ii.  is square whenever
is square whenever 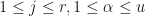 ,
,
iii.  has no non-trivial irreducible subspace whenever
has no non-trivial irreducible subspace whenever  ,
,
iv.  whenever
whenever 
v.  is square whenever
is square whenever 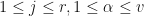 , and
, and
vi.  has no non-trivial irreducible subspace whenever
has no non-trivial irreducible subspace whenever  .
.
Given such a decomposition of into block matrices, the following are equivalent:
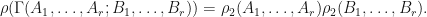
- There exists
 , a complex number and an invertible where
, a complex number and an invertible where  and
and  and where
and where  for .
for .
Corollary: (J. Van Name) If has no non-trivial invariant subspace, then  whenever
whenever 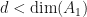 .
.
Proof: By the above result, we can choose  such that
such that  , but by the above result, we know that
, but by the above result, we know that  Q.E.D.
Q.E.D.
Statement 1 in the following theorem was originally proven by Fedja from MathOverflow, but the proof given is by Joseph Van Name (I was only able to see how quantum channels were related to after reading Fedja’s proof).
Theorem: (J. Van Name) Let 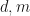 be positive integers. Suppose that is a
be positive integers. Suppose that is a  -matrix with real entries whenever
-matrix with real entries whenever 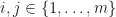 . Let be the
. Let be the 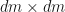 matrix that can be written as the block matrix
matrix that can be written as the block matrix

Then

2. For all , the matrices can be chosen such that 
3. If  and
and 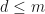 , then
, then 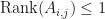 for each
for each  .
.
4. Let  denote the complete depolarizing channel. Then
denote the complete depolarizing channel. Then  .
.
Proof:
If is an 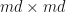 -complex matrix, then let
-complex matrix, then let  be the system of submatrices so that
be the system of submatrices so that
Let be the collection of all systems where 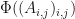 is not nilpotent. Let
is not nilpotent. Let 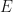 be the collection of all systems
be the collection of all systems  which are pre-trace preserving. Let
which are pre-trace preserving. Let 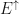 (resp
(resp  ) be the collection of all
) be the collection of all 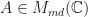 where
where 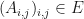 (resp ).
(resp ).
Suppose that is an -matrix where  is a quantum channel. Then
is a quantum channel. Then
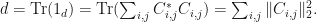
Therefore,  . Furthermore, if
. Furthermore, if  , then
, then 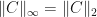 , and this is only possible if
, and this is only possible if  .
.
- Suppose now that
 Then there is a complex number and an invertible where
Then there is a complex number and an invertible where  is a quantum channel. Suppose now that is the matrix with
is a quantum channel. Suppose now that is the matrix with 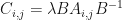 for each . In this case,
for each . In this case,
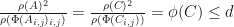 . Furthermore, if and
. Furthermore, if and  , then , so
, then , so  as well. Since is dense in
as well. Since is dense in 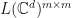 , we conclude that
, we conclude that 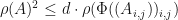 whenever .
whenever .
2. Let 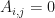 if
if 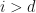 or
or  , and if
, and if  and
and  , then let be the matrix where the -th entry is
, then let be the matrix where the -th entry is  but every other entry is
but every other entry is 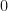 . In this case, we have
. In this case, we have  .
.
3. We shall now define functions  and
and  . Let
. Let  whenever
whenever  and
and  where
where 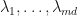 are the eigenvalues of ordered so that
are the eigenvalues of ordered so that 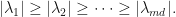 Observe that if , then
Observe that if , then 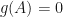 precisely when .
precisely when .
Now suppose that 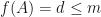 . Then let
. Then let  . Then there is some where if
. Then there is some where if  and
and 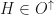 , then
, then  Now select a matrix
Now select a matrix 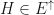 with . Then
with . Then 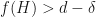 . Therefore, there is some and
. Therefore, there is some and  where if is the matrix with
where if is the matrix with  for each , then
for each , then  is a quantum channel. Therefore, we have
is a quantum channel. Therefore, we have  .
.
Thus,  Let be the eigenvalues of ordered such that
Let be the eigenvalues of ordered such that  . Then
. Then  . Therefore,
. Therefore,  , so
, so  .
.
We conclude that  . Therefore,
. Therefore,  as
as  , so which means that .
, so which means that .
4. Let  be the
be the  -matrix where all entries in are zero except for the
-matrix where all entries in are zero except for the  -th entry, and where the -th entry in is . Observe that
-th entry, and where the -th entry in is . Observe that 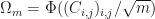 and if is a -matrix, then
and if is a -matrix, then  . Therefore,
. Therefore,  , so
, so 
Q.E.D.
Let be an inner product space. Then  is said to be a frame if there are
is said to be a frame if there are 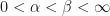 with
with 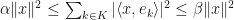 for all
for all  If
If 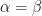 , then we say that the frame is a tight frame. In other words, is a tight frame if
, then we say that the frame is a tight frame. In other words, is a tight frame if  for all . We observe that is a tight frame precisely when
for all . We observe that is a tight frame precisely when  . An equal-norm tight frame is a tight frame where
. An equal-norm tight frame is a tight frame where 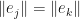 for all
for all 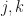 .
.
Lemma: Suppose that is either the field of real or complex numbers. There exists an equal-norm tight frame 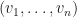 for the inner product space
for the inner product space  .
.
See Corollary 7.1 in the book An Introduction to Finite Tight Frames by Shayne F. D. Waldron for a proof of the above lemma.
Lemma: (Weyl’s inequality) Suppose that is a -matrix with eigenvalues  and singular values
and singular values  ordered such that
ordered such that 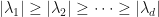 and
and  . Then
. Then 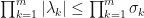 whenever
whenever  .
.
Let  be a natural number. Let
be a natural number. Let  be the matrices where
be the matrices where  such that refers to the Kronecker delta function and where the addition is taken modulo . Then
such that refers to the Kronecker delta function and where the addition is taken modulo . Then  Therefore,
Therefore,  is the maximum value of
is the maximum value of  where
where  .
.
Theorem: (J. Van Name) Suppose that 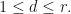
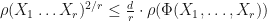 whenever .
whenever .
2. If are matrices such that  , then
, then 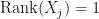 for .
for .
3. Suppose 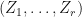 are matrices. Then the following are equivalent:
are matrices. Then the following are equivalent:
i.  is a quantum channel with
is a quantum channel with 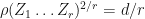 .
.
ii. there is an equal-norm tight frame  with
with  for and
for and  with
with 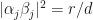 for where if
for where if  , then
, then  for .
for .
4. There are real -matrices 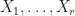 such that
such that 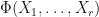 is a quantum channel and
is a quantum channel and  .
.
5. Let be the matrices in the above example. Then 
Proof:
- Suppose that
 and is a quantum channel. Then
and is a quantum channel. Then  .
.
Therefore, by the arithmetic-geometric mean inequality, we have
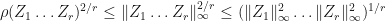

Therefore, if is a complex number, is a complex matrix, and 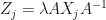 for , then
for , then 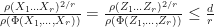 . Therefore, whenever is pre-trace preserving. We conclude that for all by continuity since the pre-trace preserving maps are dense in
. Therefore, whenever is pre-trace preserving. We conclude that for all by continuity since the pre-trace preserving maps are dense in  whenever .
whenever .
2. If , and is a quantum channel with  , then
, then  for all which implies that
for all which implies that  for . By applying continuity, we shall show that if , and
for . By applying continuity, we shall show that if , and  , then for .
, then for .
Let  be the collection of all tuples
be the collection of all tuples 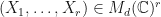 which are pre-trace preserving. Let
which are pre-trace preserving. Let  be the mapping defined by
be the mapping defined by 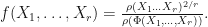
Let  be the mapping where
be the mapping where  where are the eigenvalues of ordered in such a way so that . Let
where are the eigenvalues of ordered in such a way so that . Let 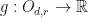 be the mapping defined by letting
be the mapping defined by letting 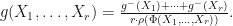
Suppose now that 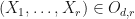 and suppose that
and suppose that  . Then for each , there is a neighborhood of where if
. Then for each , there is a neighborhood of where if 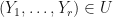 , then
, then  Therefore, select a
Therefore, select a  . Then there is some and invertible where if we set , then is a quantum channel. Now, for , let
. Then there is some and invertible where if we set , then is a quantum channel. Now, for , let  be the eigenvalues of
be the eigenvalues of  and suppose that these eigenvalues are ordered in a way so that
and suppose that these eigenvalues are ordered in a way so that  . Then
. Then
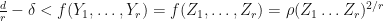
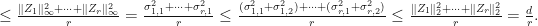
Therefore, we conclude that  and
and 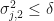 . We conclude that
. We conclude that 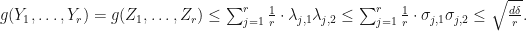 Therefore,
Therefore, 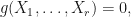 so
so  for .
for .
3.  Suppose that is a quantum channel and
Suppose that is a quantum channel and 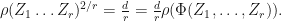 Then since
Then since  , there are vectors
, there are vectors 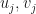 with for . In this case,
with for . In this case, 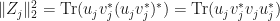
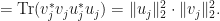 Therefore,
Therefore, 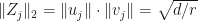 .
.
Thus, 

Since  , we have
, we have 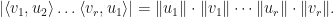
This means that there are non-zero constants 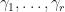 where
where 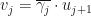 for .
for .
Now set,  . Then
. Then 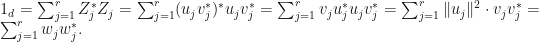 Observe that is an equal-norm tight frame with
Observe that is an equal-norm tight frame with 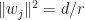 for all . In this case, if we set so that , then
for all . In this case, if we set so that , then  Therefore, we have
Therefore, we have 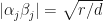 .
.
 Now suppose that is an equal-norm tight frame with for and with for where if , then for .
Now suppose that is an equal-norm tight frame with for and with for where if , then for .
Then 


Q.E.D.
Miscellaneous examples
Here are a few examples of where we give bounds for .
Example: (J. Van Name). Suppose that is completely positive. Then  .
.
Proof: Suppose that are matrices with  whenever
whenever  . Let
. Let  be -matrices where
be -matrices where  is a quantum channel and
is a quantum channel and  .
.
In this case,  , so
, so 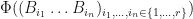 is a quantum channel. However, we have
is a quantum channel. However, we have
 .
.
Therefore, 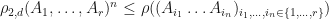 . Therefore, .
. Therefore, .
Q.E.D.
For the next example, observe that tensor products behave well with regards to the Frobenius norm. Here,  whenever
whenever 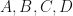 are complex matrices where the formula makes sense. In particular, if
are complex matrices where the formula makes sense. In particular, if  are orthogonal, then
are orthogonal, then  are also orthogonal.
are also orthogonal.
Example: (J. Van Name) Suppose that are -complex matrices. Then 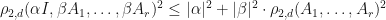 .
.
Proof: Suppose that are -complex matrices where is a quantum channel and  has as an eigenvalue with
has as an eigenvalue with 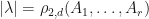 .
.
Suppose now that  . Then
. Then  is a quantum channel, and
is a quantum channel, and
 , and
, and  has
has 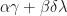 as an eigenvalue.
as an eigenvalue. 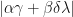 is maximized subject to when
is maximized subject to when  In this case, we have
In this case, we have 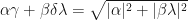 . Therefore, . Q.E.D.
. Therefore, . Q.E.D.
We conjecture that 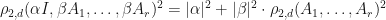 .
.
Proposition: (J. Van Name) Suppose that is a linear operator. Then 
Proof: The mapping ![[v,u]\mapsto\langle (1\otimes u^*)A,(1\otimes v^*)A\rangle](https://s0.wp.com/latex.php?latex=%5Bv%2Cu%5D%5Cmapsto%5Clangle+%281%5Cotimes+u%5E%2A%29A%2C%281%5Cotimes+v%5E%2A%29A%5Crangle&bg=ffffff&fg=111111&s=0&c=20201002) is a positive semidefinite sesquilinear form. Therefore, there is a positive semidefinite
is a positive semidefinite sesquilinear form. Therefore, there is a positive semidefinite  such that
such that 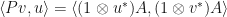 . Since is positive semidefinite, there is a basis for and non-negative
. Since is positive semidefinite, there is a basis for and non-negative  with
with  . Now set
. Now set 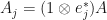 for . In this case, we have
for . In this case, we have  . Now,
. Now,
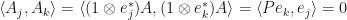 whenever
whenever  . Furthermore,
. Furthermore,
 .
.
Suppose now that is a quantum channel. Then
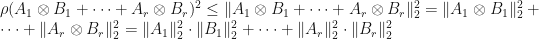
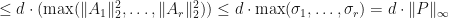 . Therefore,
. Therefore,
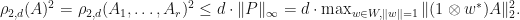
We conclude that Q.E.D.
Conclusions
We have seen that there are many different sensible notions of a spectral radius of multiple operators, but in many regards, the 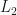 -spectral radius seems to be the correct way to generalize the spectral radius to multiple operators, and the -spectral radius seems to be a sensible approximation to the -spectral radius.
-spectral radius seems to be the correct way to generalize the spectral radius to multiple operators, and the -spectral radius seems to be a sensible approximation to the -spectral radius.
While we have produced a few basic results that initially develop the theory of the -spectral radius, computer calculations indicate that the pure mathematical theory of the -spectral radius can be developed much further. In particular, if  with
with  , and
, and  , then our computer calculations suggest that the linear operator seems to be unique up to simultaneous similarity in most cases, and seems to inherit at least to some extent many of the properties that has including rank, realness, symmetry, self-adjointness, positivity, unitarity, etc. One should therefore consider the operator as an operator obtained by reducing the dimension of the space to obtain the space while preserving the properties of in the best possible way.
, then our computer calculations suggest that the linear operator seems to be unique up to simultaneous similarity in most cases, and seems to inherit at least to some extent many of the properties that has including rank, realness, symmetry, self-adjointness, positivity, unitarity, etc. One should therefore consider the operator as an operator obtained by reducing the dimension of the space to obtain the space while preserving the properties of in the best possible way.
The -spectral radius is a mathematical function that should therefore be of interest to pure mathematicians for purely mathematical and aesthetic reasons, but we will apply the -spectral radius to measure the cryptographic security of block ciphers. The pure mathematical nature of the -spectral radius should make the -spectral radius a more appealing measure of security of block ciphers. In a future post, we shall see that the -spectral radius can be used to measure aspects of cryptographic security of block ciphers.
